Below you will find pages that utilize the taxonomy term “Backend”
java + mybatis + foreach
오래간만에 Java로 프로젝트를 할 일이 생겨서 하다보니 기본적인 것을 헤매고 있다. (무려 3시간이나 삽질하다 금요일 저녁 포기하고 퇴근했다.)
문제는 mybatis에서 foreach를 사용하는데, in sql의 조건으로 list를 넘기는 부분이 생각했던 것이 아니었는데. (결국 1cm 빗나간것이 영 엉뚱한 짓을 하고 있었던 것이다.)
curl
- 결국 보내는 List변수명과 받는 List변수명이 일치해야 하는 것이다.
curl -X 'POST' \
'http://localhost:8080/test01/select01' \
-H 'accept: */*' \
-H 'Content-Type: application/json' \
-d '{
"listTest01InVO": [
{
"id": "ID2"
},
{
"id": "ID3"
}
]
}'
Java
List의 변수명을 잘 기억하자
email + eml + sync
# EML 파일명을 Maildir 규칙에 맞게 변경 (예: 타임스탬프 활용)
for eml in *.eml; do
new_name=$(date +%s%N).$(hostname).eml
cp "$eml" "/tmp/maildir/new/$new_name"
done
어쩌다 보니 이메일을 파싱해서 특정 보험건에 대한 요율을 추출해야 하는 상황이되어 제반 준비를 하다 발견했다.
위 shell에서 “date +%s%N"의 의미를 몰라 찾아보니.
date 명령의 형식을 지정하는 파라미터였다. 음. 위 방식을 unix 나노초를 반환하는 것이다.
그런데 뒤쪽의 hostname은 왜 필요한 것일까? (그냥 식별하는 용으로 보인다.)
gcp + apigee + SpikeArrest
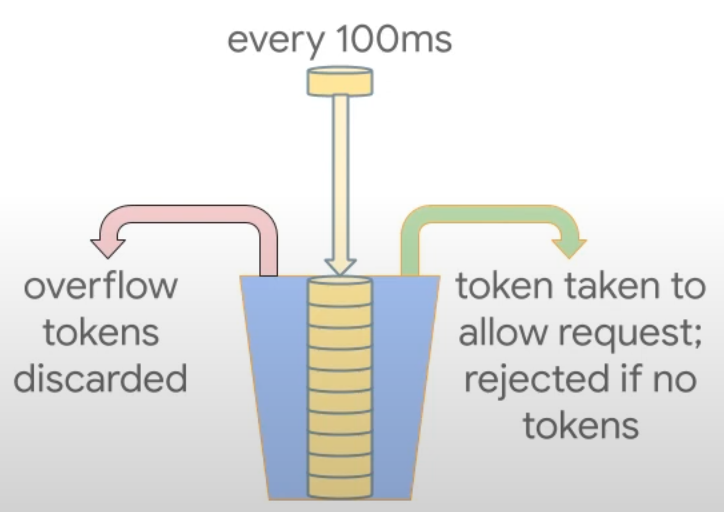 |
|---|
| SpikeArrest works |
apigee의 traffic management를 보다가 생각한다.
그 짧은 순간에 이전과 이후의 요청을 어떻게 구분한 것인지 말이다.
구글의 엔지니어들은 양동이 개념을 도입해서 요청이 들어오면 평가하는 것이 아니라, 각 요청들을 하나의 양동이에 담고, 그 양동이 시간이 되면 퍼내는 식으로 구현을 했다.
참고할 만하다.
GCP + apigee + debug
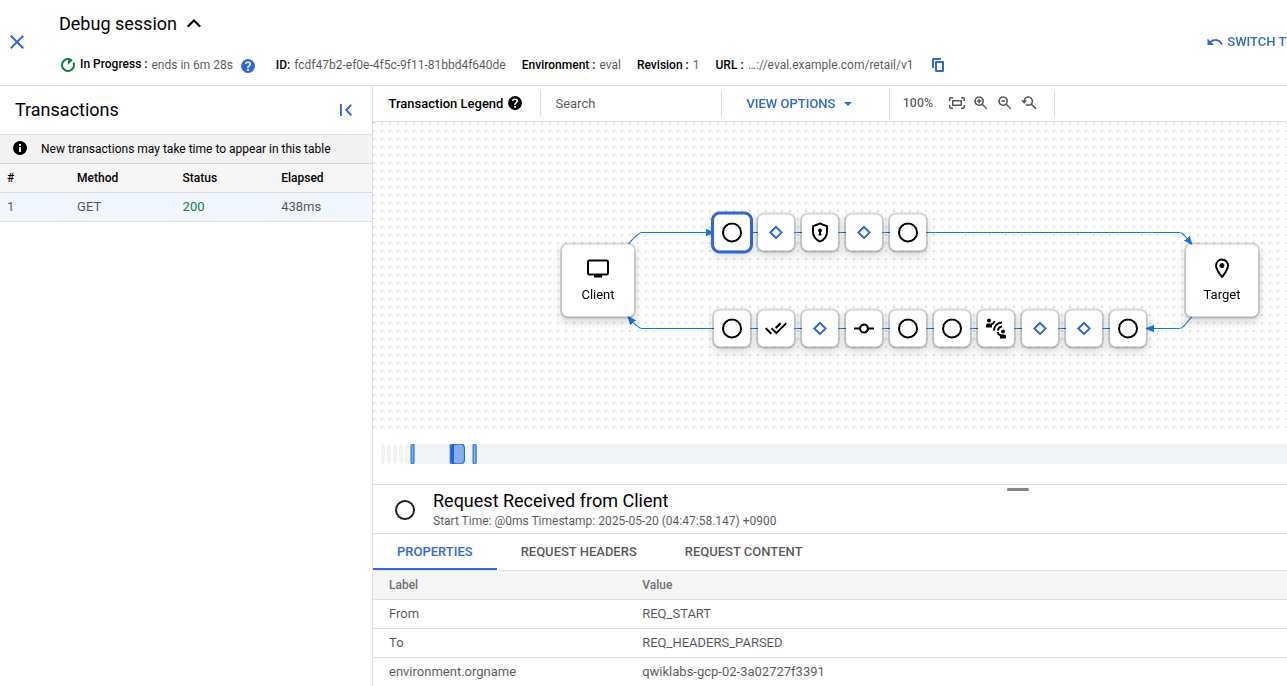 |
|---|
| apigee debug |
GCP apigee 세션을 진행하다보니 각 호출에 대해 디버깅 할 수 있는 Step이 있어 기록으로 남겨본다.
REST 응답에 meta data를 포함하는 것
 |
|---|
| rest 응답에 메타정보를 포함하는 방식 |
REST API 설계의 기본이라는 동영상을 보다보니, 데이터 이외에 메타정보를 포함하는 내용이 나온다.
REST를 구성하면서 한 번도 생각해 본적이 없는 것이라 살짝 당혹스럽다.
물론 차세대라고 불리는 SI 할 때는 응답전문에 복수의 배열이 포함될수 있음으로 배열명과 동일한 _변수를 반드시 선언하는 식으로 많이들 하긴 했었다만.
이것을 좀더 나이스한 메타정보로 어찌해 볼 생각은 왜 못했을까 싶다.
 |
|---|
| GET, POST의 용법에 대해서도 다시 생각한다 |
물론 기본은 기본이지만 나는 대부분 GET과 POST로 모든것을 다 처리하고 있었는데 말이다.
DungBeetle
700만개의 postgres table이라는 좀 자극적인 발표를 보고.
Dung Beetle을 찾아서 테스트 해본다.
- 생각보다 설정이 간단하다. toml파일 하나로 된다.
- SQL폴더에 복수의 SQL File이 있어도 된다.
- 결과 테이블은 매 요청마다 새로 생성 될 수 있다.
- 700만명의 정보라기 보다는 700만번의 request가 아니었을까 싶다.
- table name에 대해서 고민을 좀 잘하면 될 거 같다.
prefect cloud lgoin
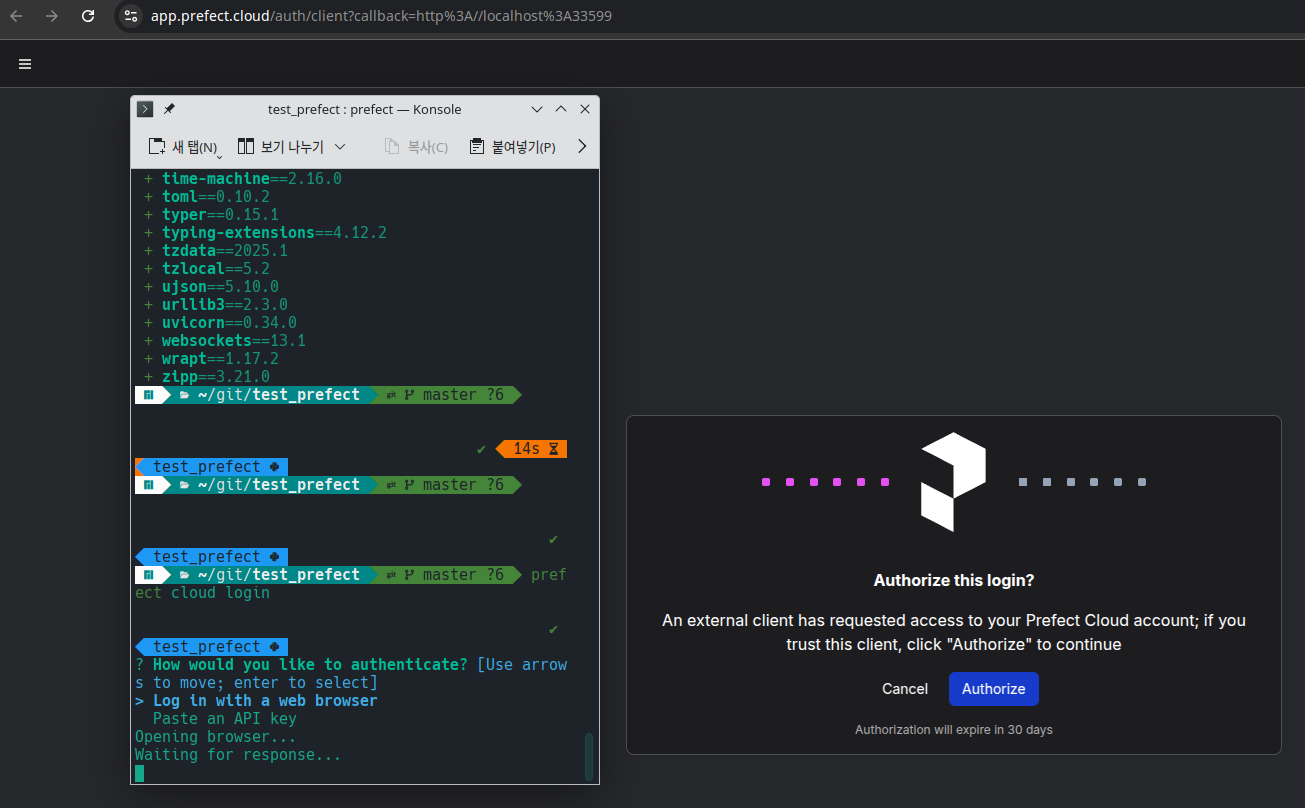 |
|---|
| Prefect 인증화면 |
Prefect를 살펴보기 위해서 Cloud에 sigin in 한 다음 따라하고 있었는데 말이다.
local cli에서 prefect module을 설치하고 cloud + login 파라메터로 실행을 하니, 진행중인 웹브라우저로 인증을 한다.
당연히 web을 통한 인터페이스만 제공되는 줄 알았는데, local 환경을 제공하는 것은 어떤의미일런지.
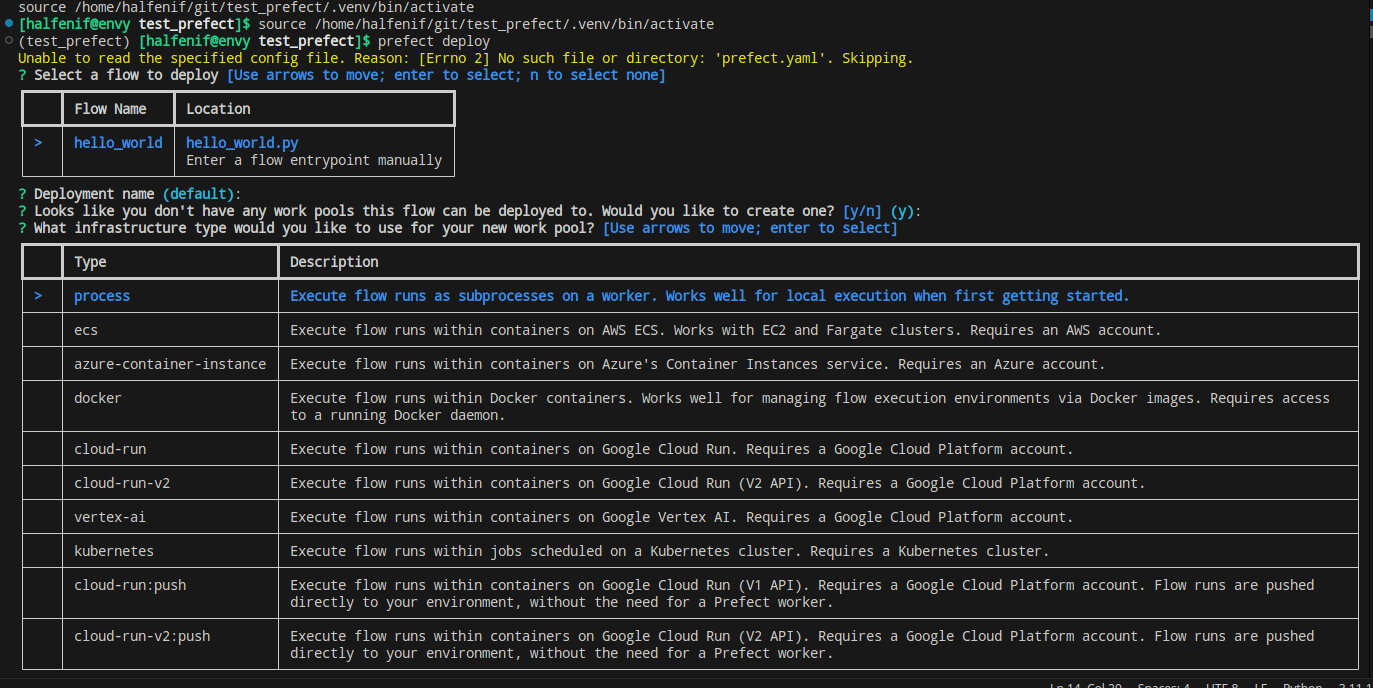 |
|---|
| Prefect local deploy 화면 |
한참을 뒤지다가 local에서 server를 띄우고 deploy를 실행 해 본다.
이런 CLI에서 본격적으로 select하는 녀석은 오래간만이다.
star vs. snowflake
dbt를 보다가 보니 이런 저런 내용이 나오는데, 누군가 star schema에 대한 언근이 있어 찾다가 MS의 Understand star schema라는 페이지를 찾았다.
좀더 구체적인 비교를 찾아 질의 해 본다.
1. 구조 (Structure)
Star Schema
- 중앙에 하나의 팩트 테이블이 있고, 이를 둘러싼 다수의 디멘션 테이블로 구성됩니다.
- 디멘션 테이블은 비정규화된(flat) 형태로 설계되며, 각 디멘션이 별도의 테이블로 저장됩니다.
- 단순한 구조를 가지며 별 모양을 띱니다.
Snowflake Schema
- 팩트 테이블은 동일하지만, 디멘션 테이블이 정규화된(normalized) 형태로 설계됩니다.
- 디멘션 테이블이 하위 디멘션으로 분할되어 복잡한 트리 구조를 형성합니다.
- 눈송이(snowflake) 모양을 닮은 구조입니다.
2. 정규화 수준 (Normalization)
Star Schema
- 디멘션 테이블이 비정규화(denormalized) 되어 있습니다.
- 하나의 디멘션 테이블에 모든 속성이 포함되며, 중복 데이터가 있을 수 있습니다.
Snowflake Schema
- 디멘션 테이블이 정규화(normalized) 되어 있습니다.
- 중복 데이터를 제거하고 디멘션 속성을 여러 테이블로 나눕니다.
3. 복잡도 (Complexity)
Star Schema
- 구조가 단순하여 이해 및 유지 관리가 용이합니다.
- 쿼리가 간단하고 빠르게 실행됩니다.
- 데이터 웨어하우스 설계 초보자나 소규모 프로젝트에 적합합니다.
Snowflake Schema
- 구조가 복잡하며, 이해 및 유지 관리가 어려울 수 있습니다.
- 정규화로 인해 테이블 간 조인(join)이 많아 쿼리 성능이 떨어질 수 - 있습니다.
- 대규모 데이터 웨어하우스나 복잡한 데이터 관계를 다룰 때 유리합니다.
4. 성능 (Performance)
Star Schema
- 조인이 적어 쿼리 성능이 일반적으로 더 우수합니다.
- 디스크 공간 사용량은 더 많을 수 있습니다(중복 데이터 때문).
Snowflake Schema
- 정규화로 인해 조인(join) 작업이 많아 쿼리 성능이 저하될 수 있습니다.
- 디스크 공간 사용은 더 적습니다(중복 데이터가 제거됨).
5. 사용 사례 (Use Cases)
Star Schema
- 단순한 데이터 분석과 빠른 응답 시간이 필요한 경우.
- BI 도구나 OLAP(Online Analytical Processing)에서 자주 사용됨.
Snowflake Schema
- 데이터 중복을 최소화하고 정규화를 통해 데이터 무결성을 유지하려는 경우.
- 복잡한 데이터 관계를 명확히 표현해야 하는 경우.
비교 요약
| 특성 | Star Schema | Snowflake Schema |
|---|---|---|
| 구조 | 비정규화된 단순 구조 | 정규화된 복잡한 구조 |
| 데이터 중복 | 있음 | 없음 |
| 성능 | 쿼리 성능이 우수 | 조인으로 인해 성능 저하 가능 |
| 설계 복잡도 | 낮음 | 높음 |
| 디스크 공간 사용 | 더 많이 필요할 수 있음 | 더 적게 필요함 |
Rust + String
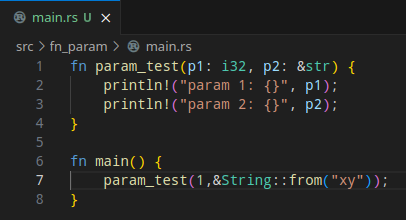 |
|---|
| Rust에서 문자를 파라미터로 넘기는 모습을 봐라 |
새해들어서 어떻게든 호기심을 유지하려고 한 해 동안 모아두었던 링크들을 정리하고, 하나씩 해 보고 있다.
Rust의 경우. 첫 번쩨 빌드하기 위한 소스의 구조를 toml에 기술해줘야 한다는 것은.. 뭔 그럴수 있다고 치자.
그 다음 파라미터를 좀 보면서 문자열을 넘기는 부분을 보다 아연실색한다.
그리고 좋다고 생각한다.
형식은 언제나 익숙해지기 마련이다. 생각을 잘 하면 매우 유용 할 것이고, 가변적인 상황을 전부 상정해서 어떻게 하려면.. 아마 방법이든 패턴이든 라이브러리든 있을 것으로 생각된다.
유효한 JSON String을 검사하는 방법
금요일 저녁. 야근을 할 계획은 없었으나, 오전중에 팀원이 적용한 서비스 선처리 권한관련 이리저리 시간을 할애하다 보니.
사람들이 하나 둘 퇴근을 한 후. 마음을 다잡고 테스트를 하다보니, 무효한 JSON String에 대한 처리가 제대로 되고 있지 않은것이 보인다.
JsonParser jsonParser = new JsonParser();
JsonElement jsonElement = jsonParser.parse(strJson);
폐쇄망이라 핸드폰으로 잠깐 구글링을 해 보고, 당연히 무효한 문자열을 파싱함에 있어 Exception을 throw 할 것으로 기대했으나.
try {
JsonObject jsonObject = jsonElement.getAsJsonObject();
} catch (IllegalStateException e) {
System.out.println("Not JSON Object");
}
퇴근을 하고, 집에 돌아와 좀더 찾다보니. 파싱 시점이 아닌 get시점에 catch하는 방법을 찾을수 있었다.
FastAPI에서 Refresh Token 생성하는 구조
토요일.
지금만들고 있는 Toy Project는 Admin Site이기 때문에, 불특정 다수를 대상으로 하는 것도 아니고 통상적인 자그마한 수준의 트랜잭션을 감당 할 예정이라 모든 요청에 인증 및 권한체크를 하는 것으로 구상을 하고 있다.
인증 후 Token의 만료시간을 30분으로 잡고 있는데, 이 경우 계속 사용을 하면(===요청을 하면), 그 만료시간을 자동으로 늘려주려주는 방식의 구조를 만들려고 한다.
알아야 하는 사항
- login을 제외한 모든 요청은 인증체크와 권한체크가 되어야 한다는 전제이다.
- 모든 요청에 인증체크가 자동으로 되기 위해서 주입(injection)을 사용한다.
- 체크를 위한 값과 체크의 결과를 응답에 섞어서 받거나 내릴수 없기 때문에 request.header와 response.header를 사용한다.
- 해당 Request, Response 객체는 fastapi가 아니고 starlette에 있다.
- dependencies 선언에 파라메터를 넣을 수 없어서, 중간 함수가 하나 필요하다.
이 정도만 있으면, 구글링을 통해서 자신이 원하는 구조를 만들 수 있겠으나 코드를 좀 살펴보면.
FastAPI 요청 로그 생성하기
목요일.
FastAPI로 요청되는 것들에 대해서 로깅을 하려고 봤더니 한 방에 안되어 좀 찾아본다.
알아야 하는 사항들
- FastAPI 모든 요청에 끼워서 사용 할 수 있는 middleware 기능이 있으며, 사용방법이 아주 다양하다.
- middleware에서 request, response를 사용 할 수 있는데, starlette.requests 등이 필요하다.
- Python Logging을 사용하기 위해서 형식을 지정하는 formatter가 필요한데, FastAPI것도 있고 따로 만들어도 된다. 나는 별도 항목으로 정리하고자 해서 별도로 만들었다.
- Logging형식을 JSON으로 하고 싶어서 찾아보니
pythonjsonlogger라고 만들어 둔 것이 있다. - logging 객체를 함수안에서 만들면… 함수를 부를 때 마다 로그가 배수로 출력된다. 1 > 2 > 4 > 8 > ..?
설치
sudo pip install starlette-context
sudo pip install python-json-logger
main.py
from starlette.requests import Request
# 로그 객체 생성
logger = logging.getLogger()
logger.setLevel(로그래밸)
handler = logging.FileHandler(로그파일명)
handler.setFormatter(만들어진 포매터를 넣는다. pythonjsonlogger 깃헙 참조)
logger.addHandler(handler)
# Define Audit Log
@app.middleware('http')
async def audit_log(request: Request, call_next):
# ----------------------------------
# Next를 안부르면....!!!!
response = await call_next(request)
saveLog(logger, request, response)
return response
유심히 볼 부분은 audit_log 위쪽에 있는 어노테이션이다. 그리고 로거 객체는 함수 밖에서 만들어야 했고, saveLog()에 request와 response를 넘겨줘서 로깅할 내용을 꺼낼 수 있도록 한다.
Jekyll minima에 Counter 구성하기
화요일.
Jekyll minima thema에는 (당연히) 기본으로 제공하는 카운터가 없어서 하나 만들어 보기로 한다.
카운터의 원리를 여러가지 생각 해 볼 수 있겠으나, 특정 URL로 요청을 하면 카운터 이미지를 되돌로주는 방식이다.
카운팅을 하기 위해서는 카운텅 숫자를 보관 할 필요가 있기에.. 그건 DB를 사용하기로 하고, 남은건 어떻게 이미지를 만들것인가? 인데.
요즘은 SVG라는 걸출한 포맷이 보편화되었기에 이미지가 아니라 String을 반환하면 되기는 한다.
알아야 하는 사항
- Python에는 SVG용 라이브러리가 아주 많은거 같은데, svgwriter가 많이 사용되는 것 같다.
- Counter를 다른 사용자 혹은 다른 곳에서 사용되면 곤란하기 때문에, 요청 ORGIN을 반드시 체크해야한다.
from os.path import join
import svgwrite
def get_counter_by_uuid(uuid: str):
# DB에서 uuid로 기 등록된 카운터를 받아오거나 없으면 신규로 Insert한다.
row = sql_get_count_by_uuid(uuid)
if row:
countNumber = row['READ_COUNT']
countStr = f'Read Count : [{countNumber}]'
else:
countStr = 'Read Count Fail!'
# 카운터 파일 저장 할 폴더를 하나 만들어 두고
filename = join(COUNTER_DATA_FOLDER, f'{uuid}.svg')
# 드로잉을 하나 만들면서 크기를 넣어주고
dwg = svgwrite.Drawing(filename, (200,16))
# 문자열을 집어 넣는다
dwg.add(dwg.text(countStr, insert=(0, 13), fill='black'))
# 파일로 저장한다
dwg.save()
# 파일명을 반환한다
return filename
자 이제 SVG파일을 만들었으면.. (이걸 열어보면 HTML Element이다.) 반환을 해야 하는데, 사용하고 있는 FastAPI에는 FileResponse라는 아주 좋은 기능이 있다.
Fast API JWT Example을 실행보면서 검토할 사항들
토요일.
운동을 가자고 하는 집사람의 요구를 쌩까면서 Java Spring으로 구현했던 JWT와 Python FastAPI에서 Example로 제공하는 JWT를 비교 해 보고 있다.
먼저 알아야 하는 사항
- OAuth2PasswordRequestForm
- OAuth2PasswordBearer
이 두 가지가 무엇인지 정확하게 식별해놓지 않은 상태에서 Example을 보고 따라하면 통상적으로 하려고 했던것에서 많이 어긋나는 상황이 발생하는듯하다.
OAuth2PasswordRequestForm
아래 이미지 두 개를 보자.

저 오른쪽 노란색 자물쇠가 있는 함수와 없는 함수의 차이를 생각하자.
@app.get("/items_fastapi_jwt/")
async def read_items(token: str = Depends(oauth2_scheme)):
return {"token": token}
저 자물쇠가 나오는 조건은 OAuth2PasswordBearer유형의 Dependency Injection인 경우 출력되는 것으로 유추된다.
VSCode + FastAPI 디버깅을 하려는데 No operations defined in spec!
금요일.
아주 예전에 FastAPI에서 JWT 구현했던 것을 끄집어 내서 Toy Project에 붙여넣으며 VSCode에서 디버깅을 하려는데 함수가 하나도 보이지 않는다.

No operations defined in spec!
이 말의 의미를 찬찬히 되새겨봤다면 금방 이해를 했을터인데, 다른 문제인가 싶어서 좀 해매기 시작한다.
# VSCOde Debug용 main은 아래쪽에 있어야 한다.
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
디버깅을 위해 만들어둔 ****name****을 소스정리하면서 위쪽으로 아무생각 없이 올려두었더니, 그 아래쪽으로는 인식을 못했나 보다.
결론
Stack Overflow에 뭔가를 찾으려 해도 키워드가 애매하면 엉뚱한 것만 나온다.
Python SQLAlchemy + MySQL 파라메터 형식에 대해서
목요일.
아주 예전에 Oracle로 구현해뒀던 JWT를 다시 꺼내서 MySql로 바꾸는 작업을 하고 있었다.
sql = """
SELECT USER_ID
,USER_NAME
,PASSWORD
FROM TB_USER_BAS
WHERE USER_ID = :USER_ID
"""
params = { "USER_ID": userid }
Argument 2 must be Tuple or List!
변경된 부분은 아마도 Python에서 MySql을 사용하기 위해 Mysql Connector를 다시 설정해야 하는 부분이 아니었을까 싶지만, 메시지는 매우 당혹스러운 느낌으로 다가온다.
sql = """
SELECT USER_ID
,USER_NAME
,PASSWORD
FROM TB_USER_BAS
WHERE USER_ID = %(USER_ID)s
"""
params = { "USER_ID": userid }
한참을 찾다가 MySql Connector Python Page에서 표현식이 다른 것을 보고 적용을 해 보니 된다.
Python base64 decode 에러나는 상황
월요일.
아주가끔은 아니고 한 10번에 한 번은 아래와 같은 오류가 발생했다.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte
이것에 대해서 찾아보면 utf-8이 3Byte라서.. 어쩌구 하는 게시물도 있기는 했지만 테스트 해보니 정답은 아닌거 같고.
def getDecode(msg):
msg_byte = base64.b64decode(msg)
# 원래코드
return msg_byte.decode('utf-8')
# 변경된 코드
return msg_byte.decode('utf-16-be')
결론(아직까지는 문제없음)
- utf-8을 utf-16-be로 바꾼다 (utf-16, utf-16-be, utf-16-le의 차이점도 알아두면 나쁘지 않다.)
- 이런저런 사정으로 utf-8에서 제외되는 문자가 있는 모양이다.
- utf-8 vs. utf-16의 문제가 아니었다.
python: Invalid base64-encoded string: number of data characters (37) cannot be 1 more than a multiple of 4
이번에는 이런 오류가 발생하고 있어 구글링을 해 보니 stack overflow에 바로 해당 내용이 나온다