Below you will find pages that utilize the taxonomy term “Data”
OTEL-based Observanility
아침에 Pentaho11 관련 웨비나 링크가 이메일로 와서 보다고 보니 “OTEL-based Observanility"라는 단어가 보여 찾아본다
개발자, IT 운영자, DevOps 엔지니어, SRE(사이트 안정성 엔지니어)는 빌드하거나 운영하는 애플리케이션의 성능과 상태에 대한 책임이 있습니다. 애플리케이션이 정상인지, 의도한 대로 작동하는지 여부를 확인하는 데 사용되는 정보를 원격 분석 데이터라고 합니다. 기술 제공업체에서 원격 분석 데이터를 수집하기 위해 에이전트를 생성했지만, 이러한 에이전트를 사용할 경우 해당 제공업체가 아닌 다른 제공업체를 이용할 수 없게 됩니다. OpenTelemetry는 원격 분석 데이터를 위한 단일 개방형 표준과 클라우드 네이티브 애플리케이션에서 데이터가 모니터링되고 분석할 수 있도록 데이터를 수집하고 내보내기 위한 기술을 생성합니다.
물론 이것은 구글의 설명이지만, Pentaho가 이것을 의미하며 자료를 작성했는지 현재로서는 확신하지 못한다.
pentaho + template_sql
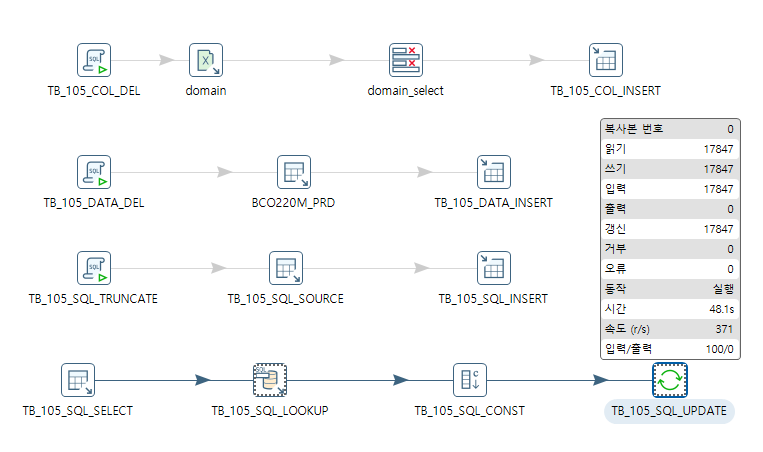 |
|---|
| 동적으로 SQL을 실행하기 위한. |
작업을 진행하다 보니 1,000만건 정도의 데이터를 확인 할 필요가 있었다.
- 대상 테이블 + 컬럼은 100개
- 대상 데이터는 10만건
- 결론적으로 1,000만건
한 방에 하려고 했더니 잘 안되서, 체크(select)하는 SQL을 테이블에 넣어 하나씩 호출해서 점검하는 방식으로 하기로 한다.
- Dynamic SQL Row를 설정하다보니 Template SQL이라는 입력값을 어떻게 처리 할런지 고민했으나, Help아이콘을 눌러 설명을 읽어보니, 결론적으로 받아낼 변수를 추출하기 위한 것이다.
설명을 잘 읽어보자.
CREATE_MODEL 진행상태 확인
BigQuery에서 create model을 실행 후
This query will process 41.76 MB (ML) when run. Depending on the model type and training data size, the training job can take minutes or even hours.
이런 메시지가 하단에 출력되고는, 이 녀석이 진행중인지 도통 알수가 없는 상태가 되어, 혹시나 하고 진헹상태를 찾아볼수 있는가 싶었지만.
SELECT
job_id,
state,
creation_time,
start_time,
end_time,
error_result
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_USER
WHERE
job_type = 'QUERY'
AND statement_type = 'CREATE_MODEL'
ORDER BY
creation_time DESC
LIMIT 10;
역시나 결과가 안 나온다.
console + data
gcloud config set project qwiklabs-gcp-02-806cc13914e8
gcloud config list project
bq show bigquery-public-data:samples.shakespeare
bq query --use_legacy_sql=false \
'SELECT
word,
SUM(word_count) AS count
FROM
`bigquery-public-data`.samples.shakespeare
WHERE
word LIKE "%raisin%"
GROUP BY
word'
Use the bq ls command to list any existing datasets in your project:
# 현재 내 dataset
bq ls
# 오픈 데이터셋
bq ls bigquery-public-data:
# make dataset
bq mk babynames
curl -LO http://www.ssa.gov/OACT/babynames/names.zip
unzip names.zip
# 스키마 지정해서 업로드
bq load babynames.names2010 yob2010.txt name:string,gender:string,count:integer
# 확인
bq show babynames.names2010
bq query "SELECT name,count FROM babynames.names2010 WHERE gender = 'F' ORDER BY count DESC LIMIT 5"
# 지우는 것도 가능
bq rm -r babynames
CVID-19 오픈 데이터 세트
Serverless dataflow
- Beam의 가장 큰 특징은 이식성임.
- 이식성 API(Portability API)라고 불림.
- SDK와 러너가 서로 균일하게 작동할 수 있음
[Separating compute and storage with Dataflow]
-
Dataflow
-
Dataflow Shuffle Service GroupByKey: GroupByKey는 전체 데이터를 셔플하기 때문에 비용이 크고, 성능 저하가 있을 수 있어요. 가능하면 CombinePerKey 같은 변형으로 대체하는 것이 좋습니다. CoGroupByKey: 두 개 이상의 데이터셋을 key 기준으로 join할 때. 예: 사용자 정보와 구매 이력, 학생과 성적 등. 각 PCollection은 key-value 쌍이어야 하며, key는 동일한 타입이어야 함 Combine: 데이터에 대해 집계 연산을 수행하는 트랜스폼입니다. 예를 들어 합계, 평균, 최대값 등을 구할 수 있어요. 두 가지 주요 변형이 있습니다: CombineGlobally: 전체 데이터에 대해 집계 CombinePerKey: key별로 집계
Trifacta
Google StudyLab을 살펴보다 Dataprep에서 Trifacta를 발견하고 매우 흥미로와한다. 이미 데이터 준비분야에서는 오래된 내용인것 같지만, 정보가 많지 않은 이유는 무엇일까 궁금하지만, 찾은 동영상은 이것을 참고하면 될 것 같다.
통상적인 ETL도구 모습이다.
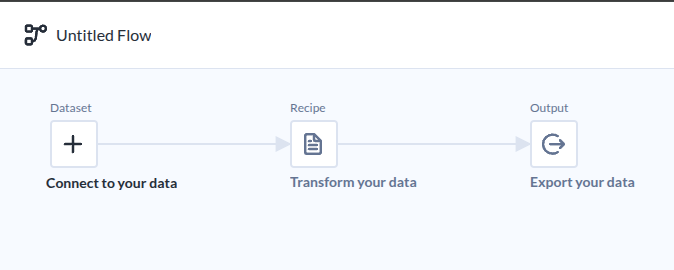 |
|---|
| Flow라는 이름으로 부르고 있다. |
데이터 소스가 아주 많은데..
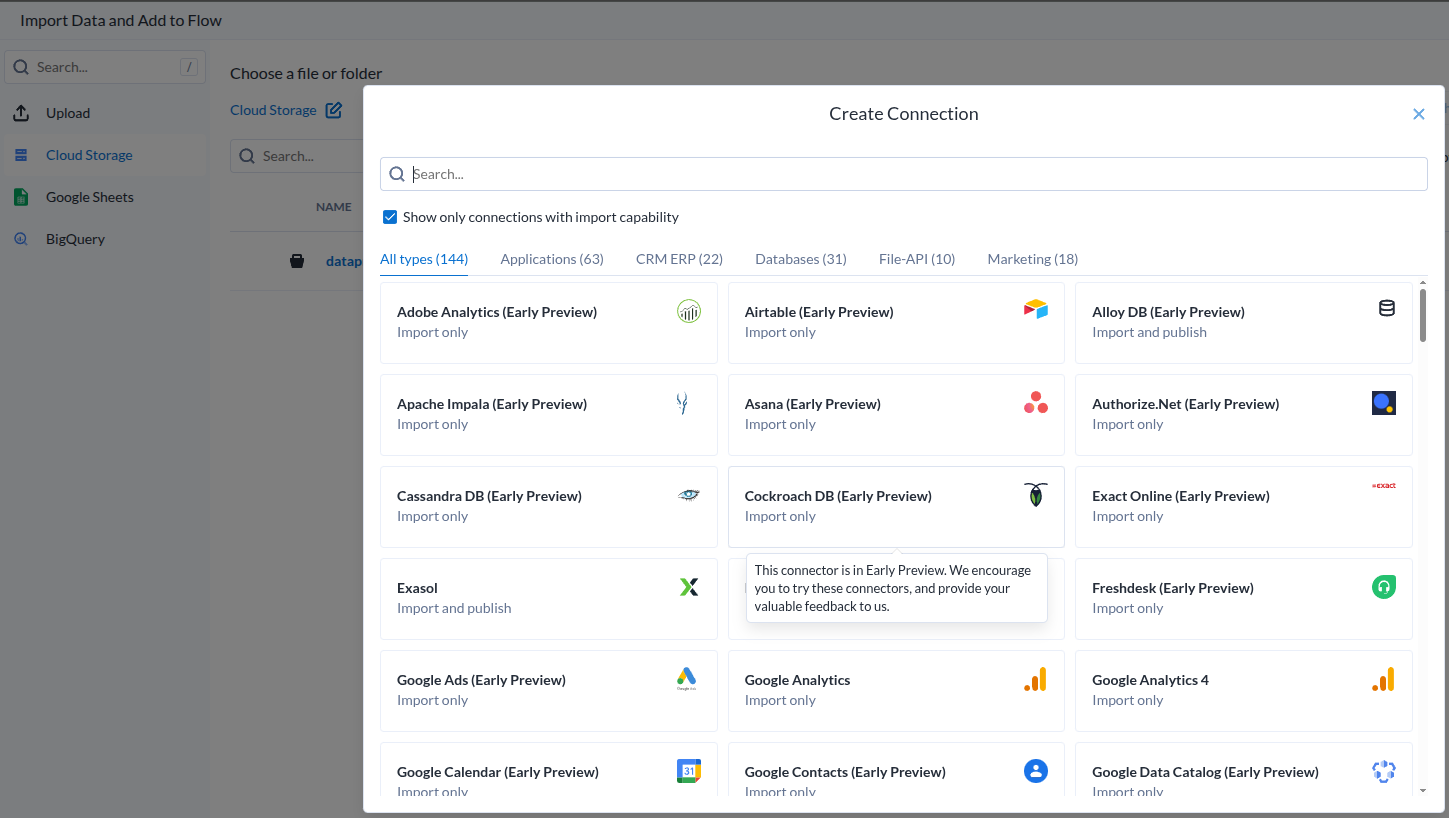 |
|---|
| Add Dataset |
- 과연 얼마나 효과적으로 작용할 것인지는 해보기 전에는 모른다.
추가하기 전에 미리보기가 가능하다.
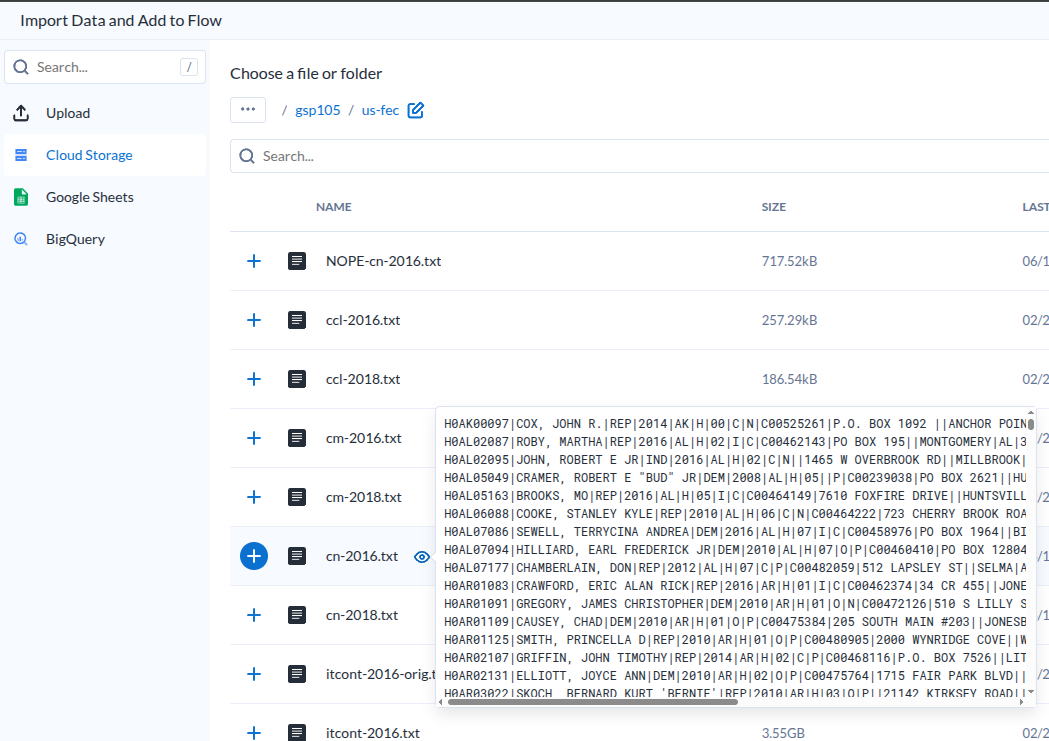 |
|---|
| Dataset Preview |
- 이렇다는 이야기는 요청이 있을 떄 준비하는것이겠지?
- 설마 미리보기를 미리 다 만들어 두나?
데이터셋을 추가하면 기본 흐름을 잡아준다마는.
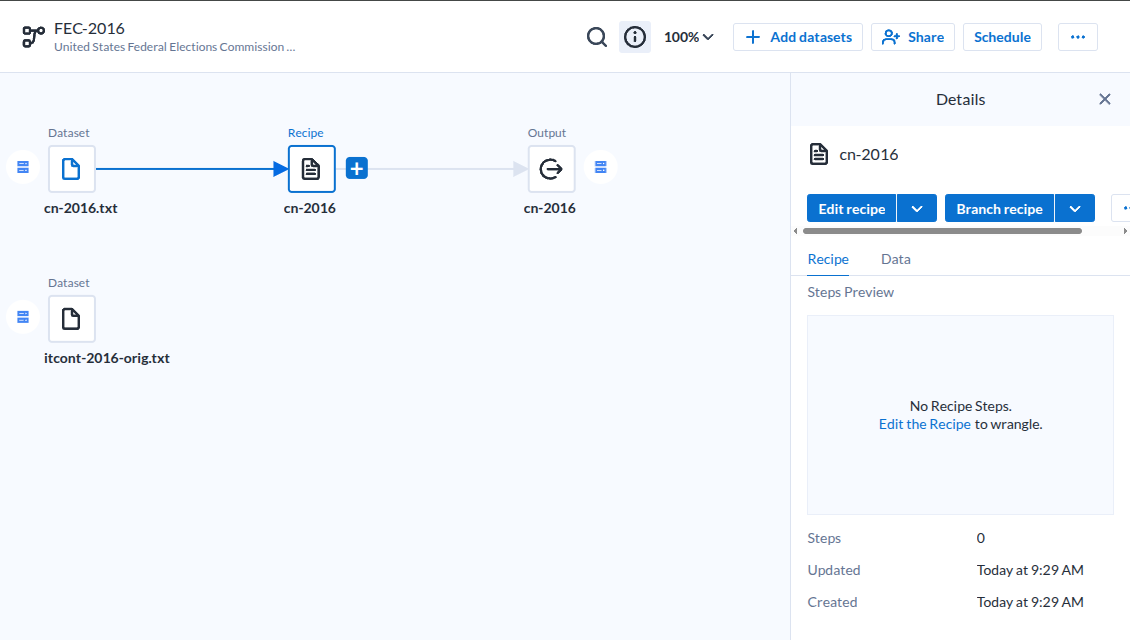 |
|---|
| Dataset-Recipe-Output |
- 딱히 효과적이라고 느끼지 못했다.
레시피로 들어가면 보여지는 저 준비 이미지가
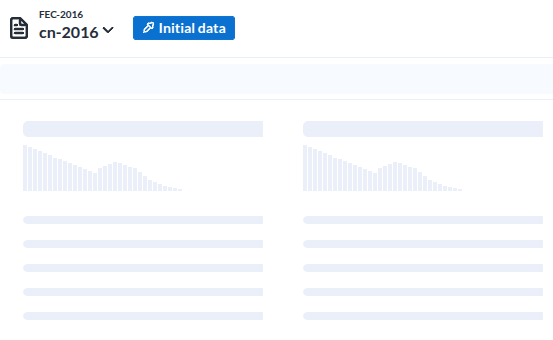 |
|---|
| Load Data |
- 이 녀석에가 가장 인상적이었던 부분은 데이터 각 컬럼을 분석해서 컬럼 상단에 표시한다는 점이다
- 이것은 이 도구가 지향하고 있는바. 준 데이터의 준비를 위한것이라는 목적에 매우 부합하는 UI라는 생각이 들었다
- 저 준비이미지는가 나타내는 각 컬럼의 시계열분포를 의미하는 형상이 매우 적절하다는 생각이다.
데이터가 로딩된 모습
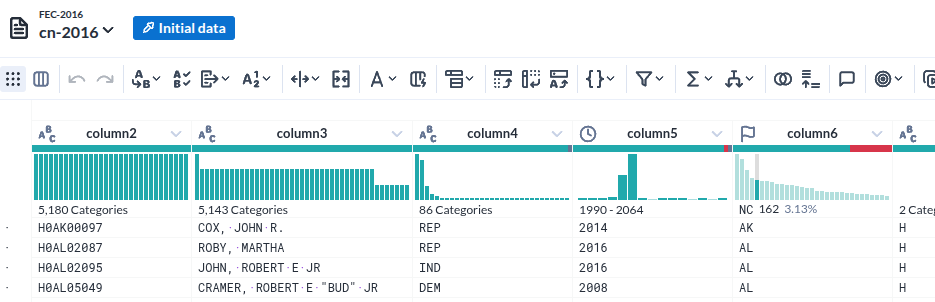 |
|---|
| Column head |
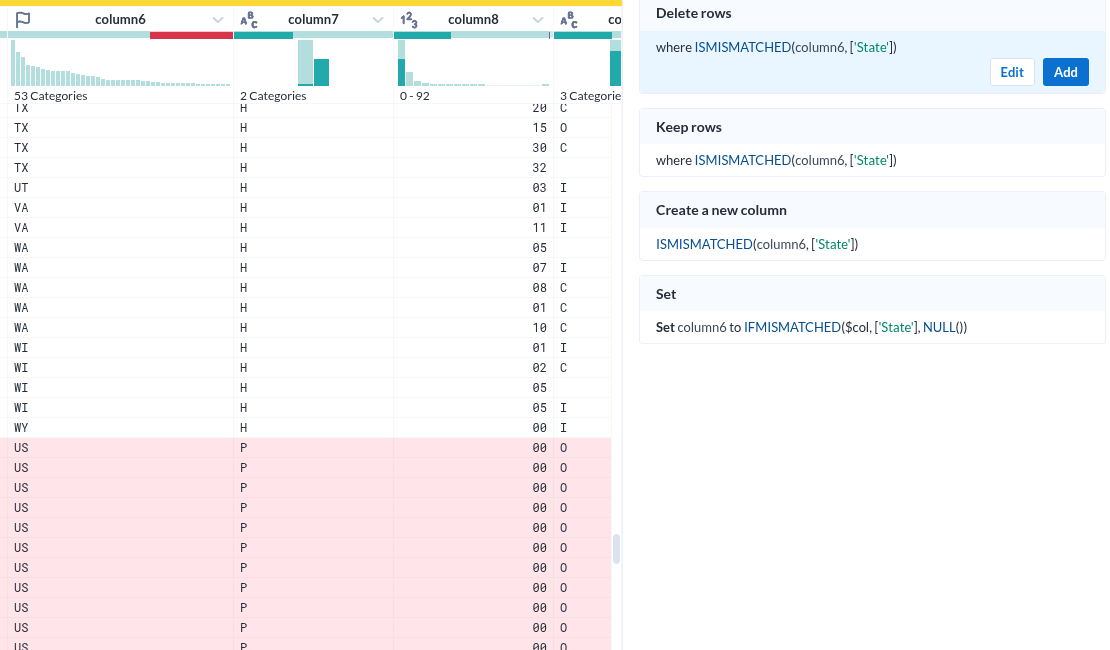
- 각 컬럼의 특성(데이터 형)을 인식한 것이 인상적이다
- 그것을 바탕으로 오류(붉게 표시된 부분) 여부까지 표시한다
- 물론 데이터의 분포를 시계열과 %로 표시하는 것은 기본이다.
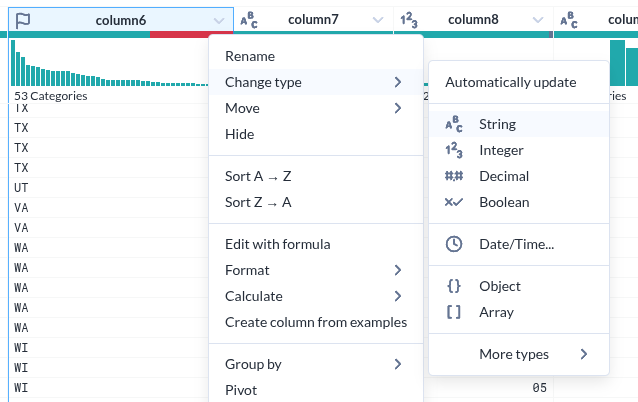
- 그런데 그 표시가 준부가 아니다. 그것을 기반으로 조작이 가능하다.
컬럼 상세
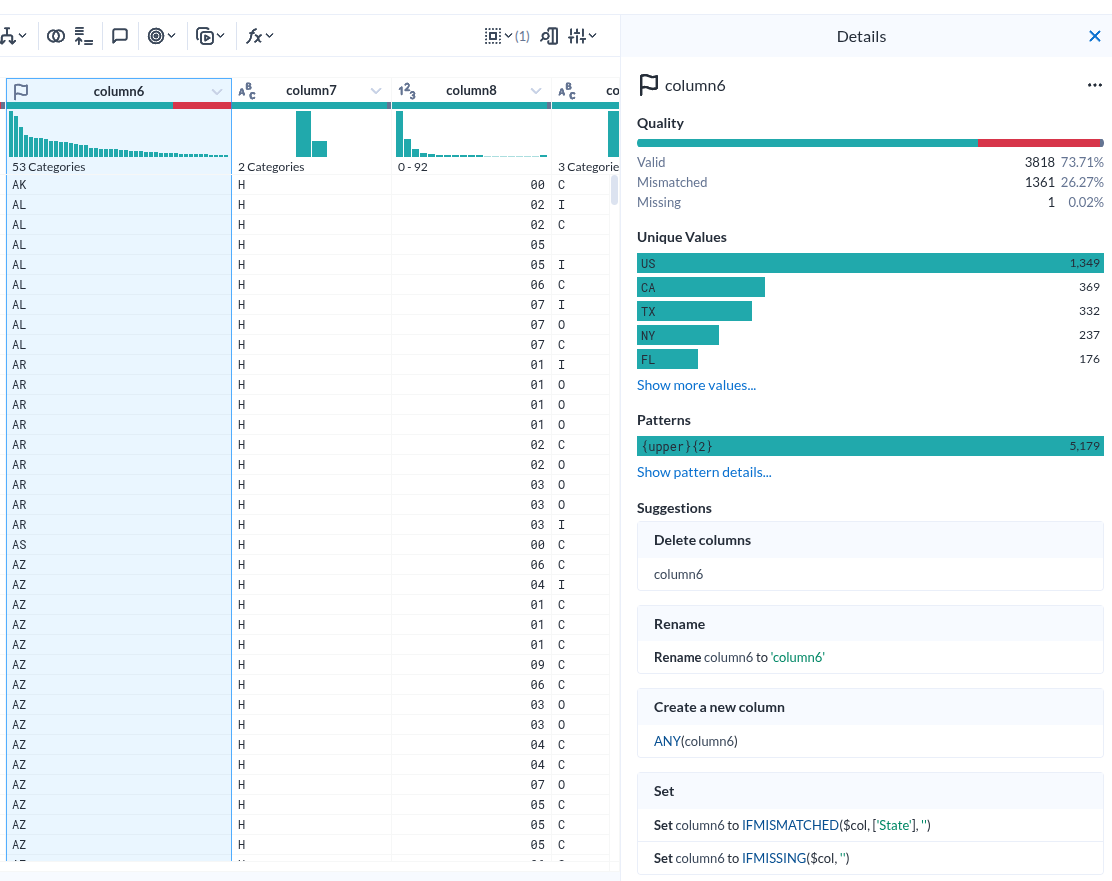 |
|---|
| Column details |
- Unique Values 하나만 해도 충분히 도움이 될 거 같다.
컬럼내 데이터 필터를 위한 선택
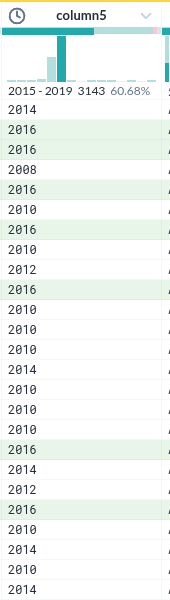 |
|---|
| 시계열에서 특정 조건을 선택한 모습 |
- 컬럼 헤더에서 시계열의 한 조건을 선택하면 아래 실제 데이터가 하일라이트 되는 것은 누가 생각해 낸 아이디어일까?
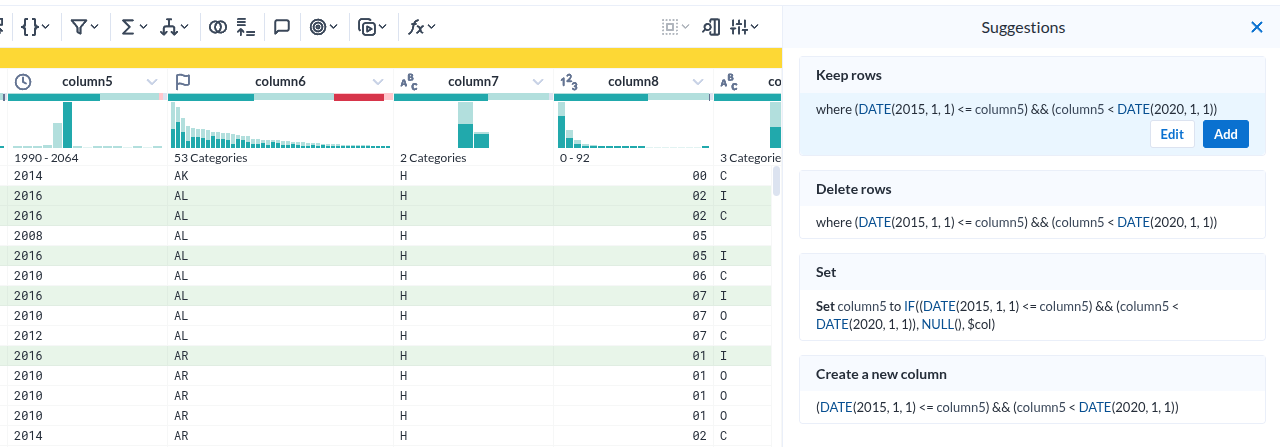 |
|---|
| Image Desc. |
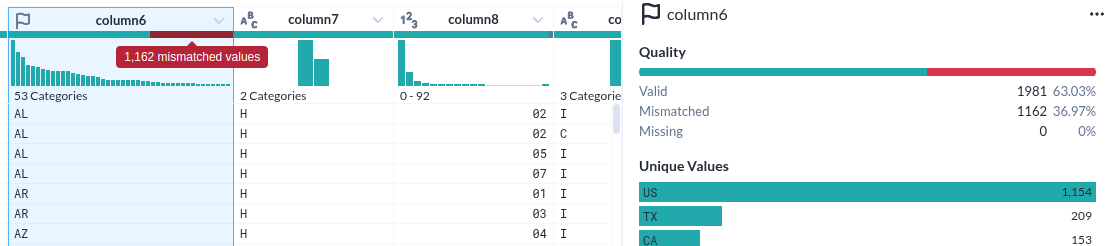 |
|---|
| Image Desc. |
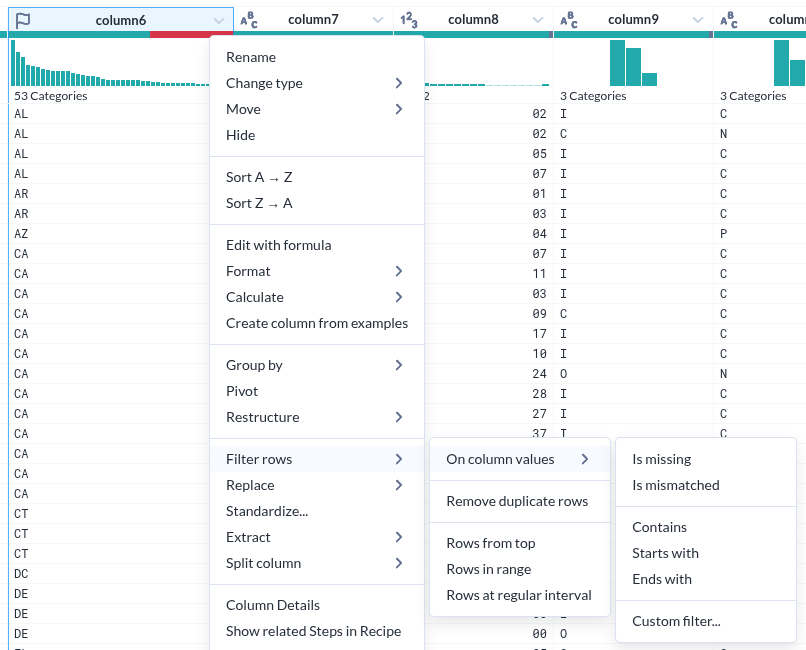 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |