Trifacta
Google StudyLab을 살펴보다 Dataprep에서 Trifacta를 발견하고 매우 흥미로와한다. 이미 데이터 준비분야에서는 오래된 내용인것 같지만, 정보가 많지 않은 이유는 무엇일까 궁금하지만, 찾은 동영상은 이것을 참고하면 될 것 같다.
통상적인 ETL도구 모습이다.
 |
|---|
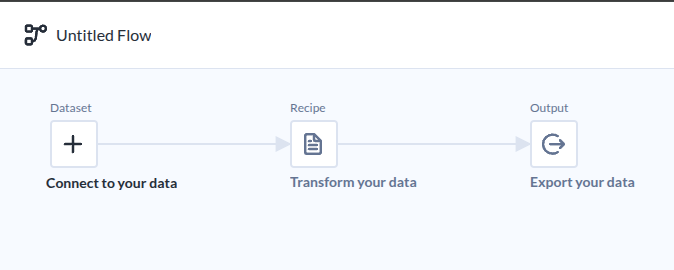
| Flow라는 이름으로 부르고 있다. |
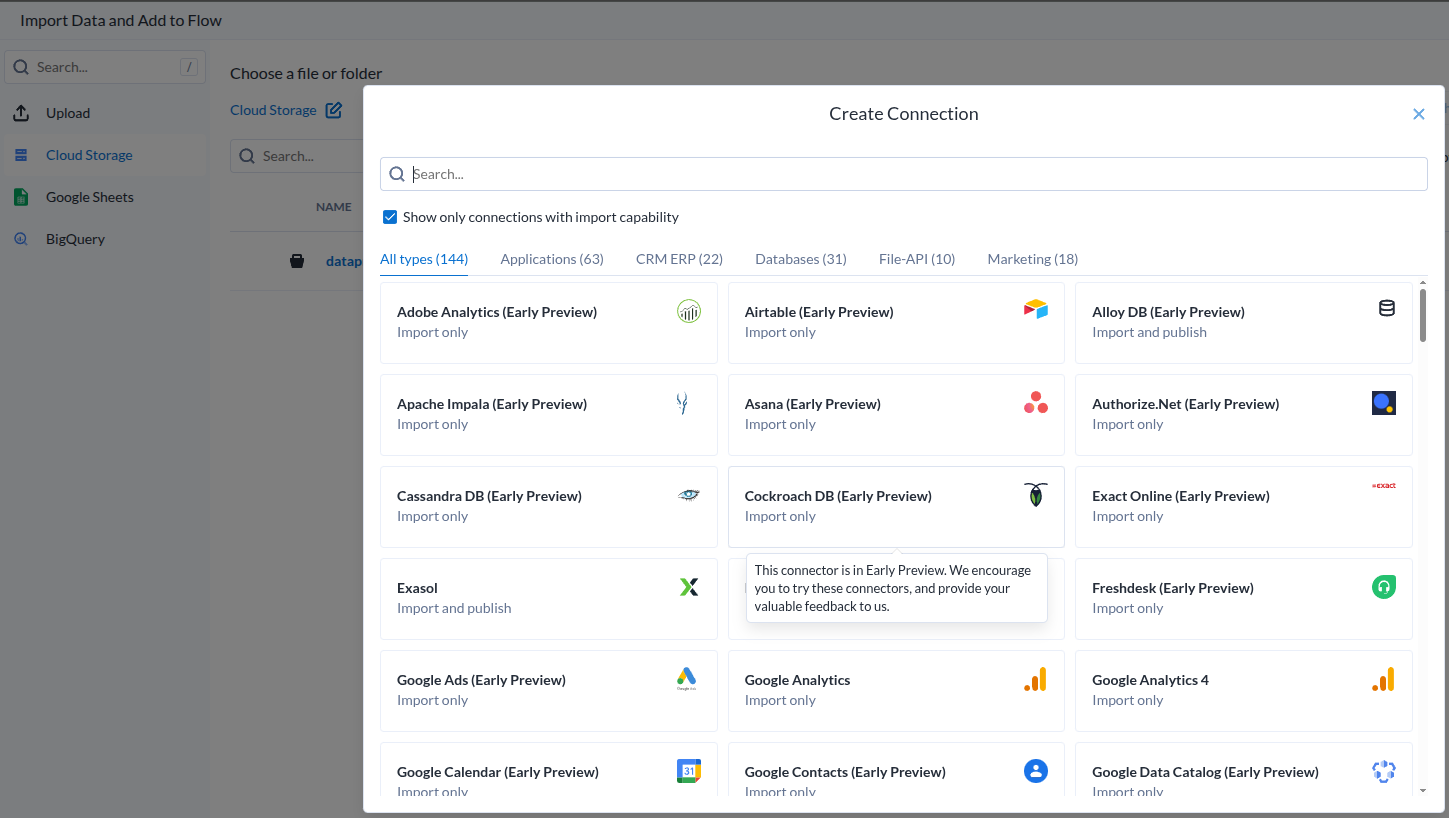
데이터 소스가 아주 많은데..
 |
|---|
| Add Dataset |
- 과연 얼마나 효과적으로 작용할 것인지는 해보기 전에는 모른다.
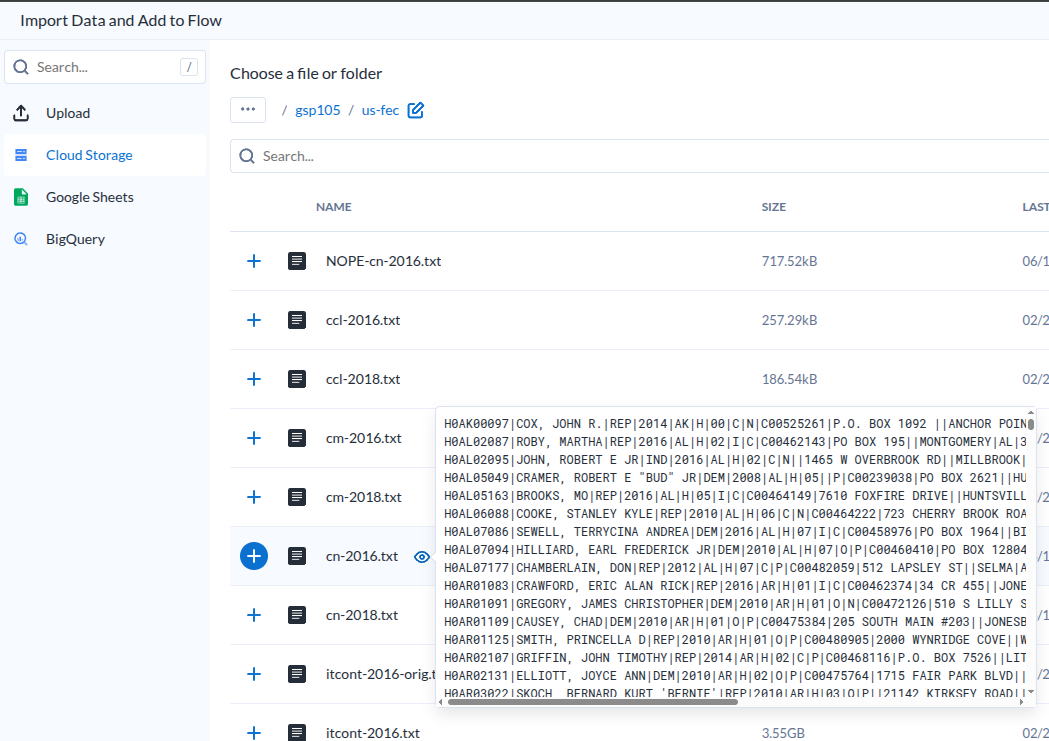
추가하기 전에 미리보기가 가능하다.
 |
|---|
| Dataset Preview |
- 이렇다는 이야기는 요청이 있을 떄 준비하는것이겠지?
- 설마 미리보기를 미리 다 만들어 두나?
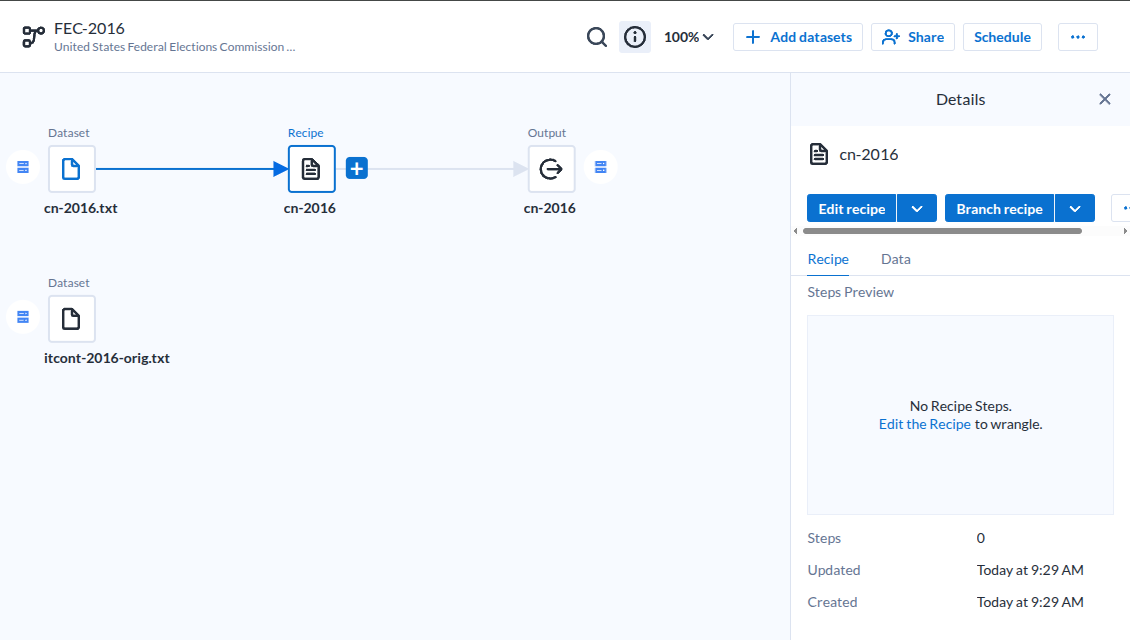
데이터셋을 추가하면 기본 흐름을 잡아준다마는.
 |
|---|
| Dataset-Recipe-Output |
- 딱히 효과적이라고 느끼지 못했다.
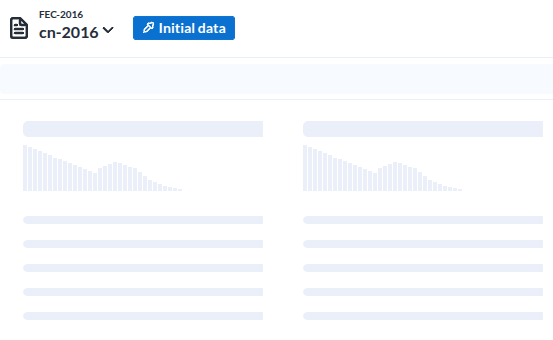
레시피로 들어가면 보여지는 저 준비 이미지가
 |
|---|
| Load Data |
- 이 녀석에가 가장 인상적이었던 부분은 데이터 각 컬럼을 분석해서 컬럼 상단에 표시한다는 점이다
- 이것은 이 도구가 지향하고 있는바. 준 데이터의 준비를 위한것이라는 목적에 매우 부합하는 UI라는 생각이 들었다
- 저 준비이미지는가 나타내는 각 컬럼의 시계열분포를 의미하는 형상이 매우 적절하다는 생각이다.
데이터가 로딩된 모습
 |
|---|
| Column head |
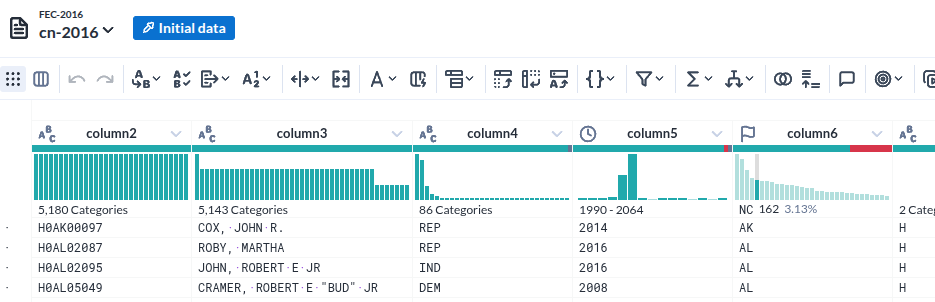
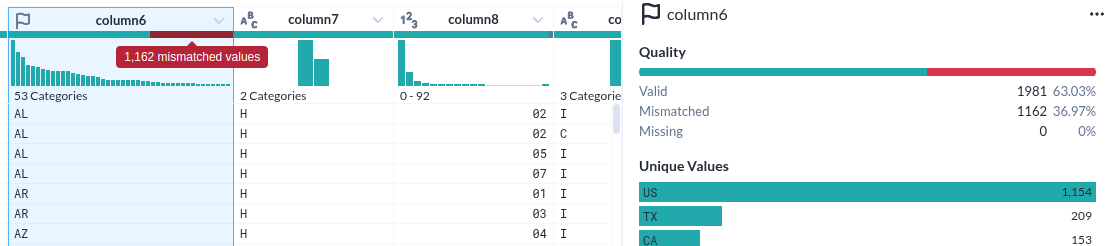
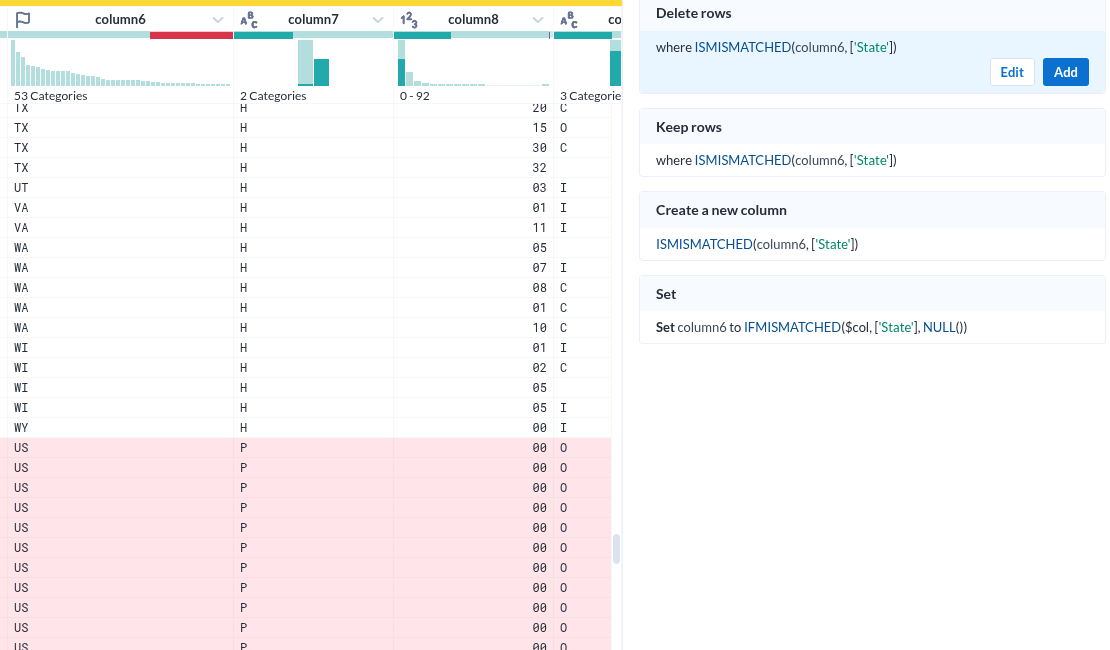
- 각 컬럼의 특성(데이터 형)을 인식한 것이 인상적이다
- 그것을 바탕으로 오류(붉게 표시된 부분) 여부까지 표시한다
- 물론 데이터의 분포를 시계열과 %로 표시하는 것은 기본이다.
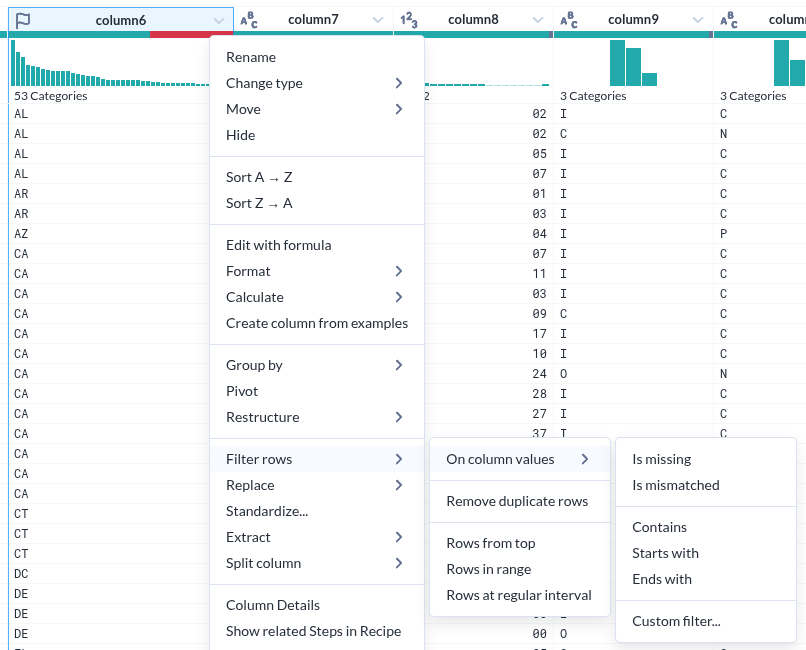
- 그런데 그 표시가 준부가 아니다. 그것을 기반으로 조작이 가능하다.
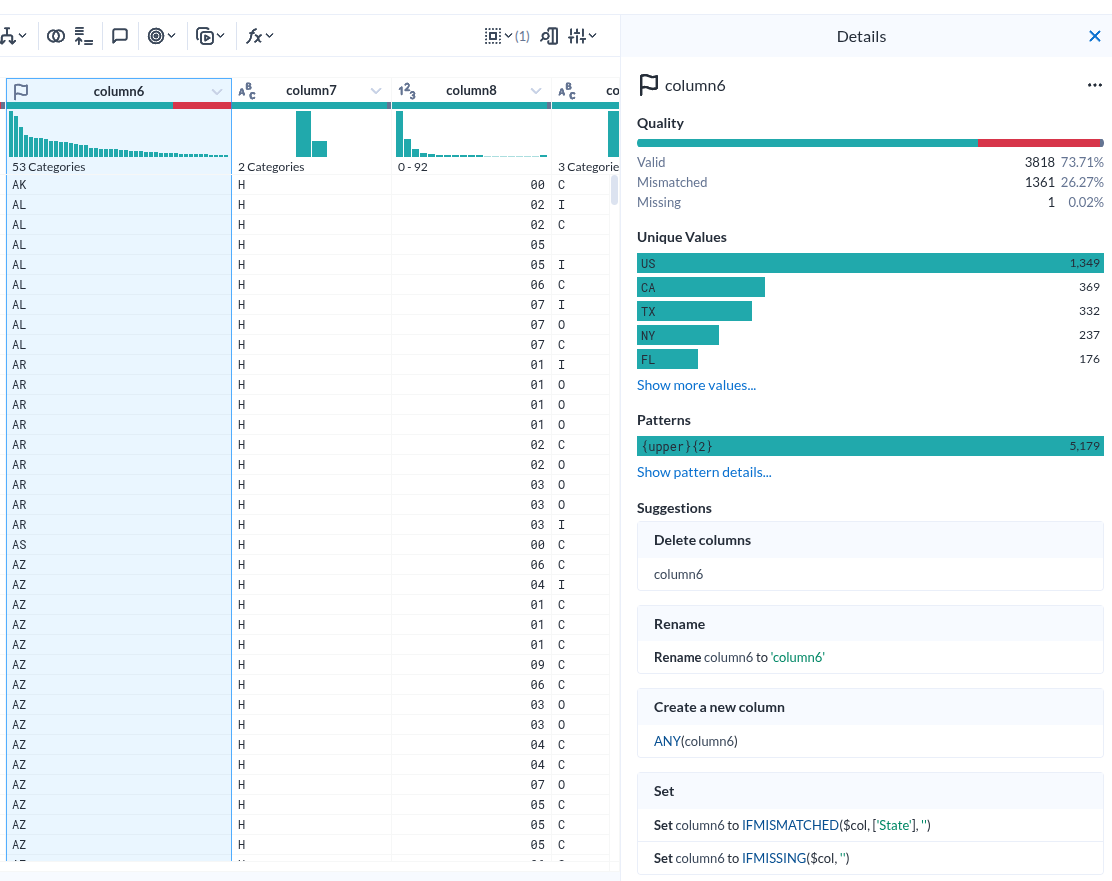
컬럼 상세
 |
|---|
| Column details |
- Unique Values 하나만 해도 충분히 도움이 될 거 같다.
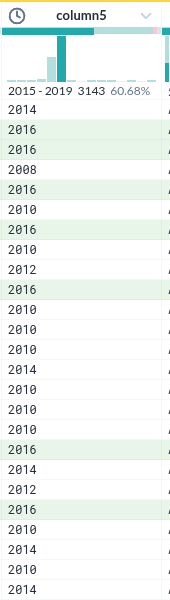
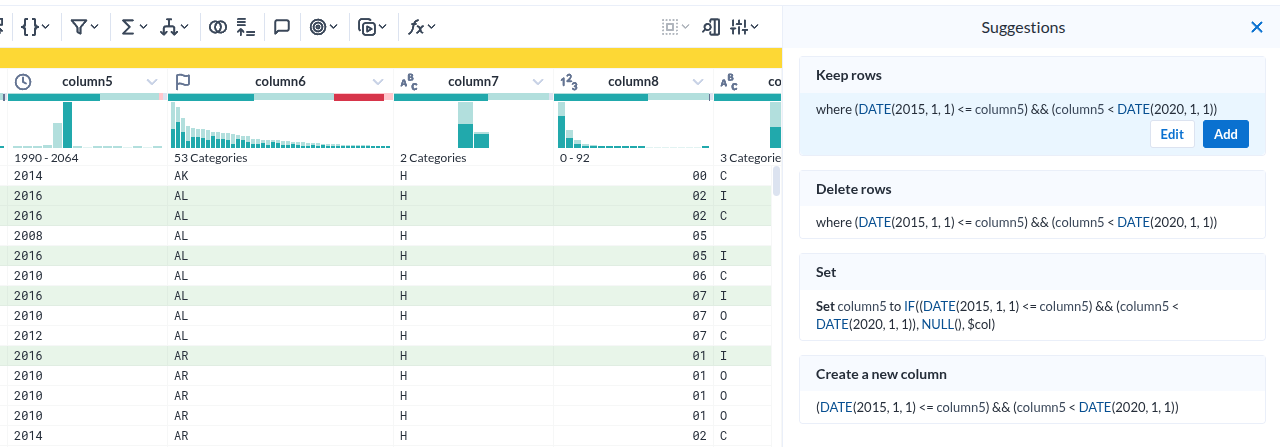
컬럼내 데이터 필터를 위한 선택
 |
|---|
| 시계열에서 특정 조건을 선택한 모습 |
- 컬럼 헤더에서 시계열의 한 조건을 선택하면 아래 실제 데이터가 하일라이트 되는 것은 누가 생각해 낸 아이디어일까?
 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |
 |
|---|
| Image Desc. |