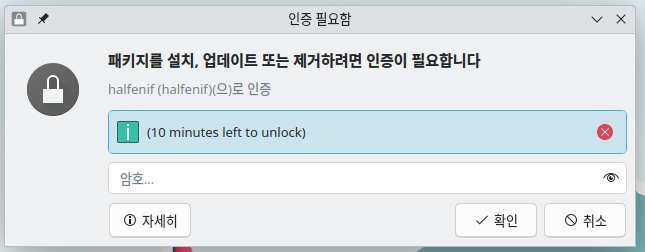
Majaro Package 설치시 인증이 틀린경우
 |
|---|
| 10분 뒤에 다시 하세요 |
Web에서 인증하는 경우가 아니라 Local에서 패키지설치 인증을 하는 동안 비밀번호를 틀리자 보이는 UI.
나름 신선하다. 꼭 필요했을까? 필요 한 거 같다.
goLang slice에서 cap의 개념을 발견하다.
goLang Tour의 slice를 해보고 있었다.
slice라는 것은 python에서도 자연스러운 것이었으나, goLang에서 가장 크게 혼동되는 것은 cap이라는 개념이 있는 것 + 기존 slice에 append하는 경우에, cap이 모자라면 +1이 아니라 +2 해서 생성이 되는 것을 발견한다.
이거 생각 잘 하고. 그 특성을 이해 하고 써야겠는걸?
package main
import "fmt"
func main() {
var s []int
printSlice(s)
// append wprks on nil slices
s = append(s, 0)
printSlice(s)
// append를 하면 len==1이 되는 것은 당연해 보이는데, cap==2가 되는 이유는 무엇일까?
// len을 강제로 2로 변경 해 보면 늘어나는 것을 볼 수 있다.
// s = s[:2]
// printSlice(s)
// The slice grows as needed
// 위에서는 nil에서 append하면 cap==2가 되었는데. cap==2인 상태에서 append하면 여전히 2이다.
// 뭔가 규칙이 있나?
s = append(s, 1)
printSlice(s)
// We can add more than one element at a time
// cap이 apped결과보다 작을 경우에, cap+1이 되어 생성되는 것으로 보인다.
s = append(s, 2, 3, 4)
printSlice(s)
// 강제로 len을 설정하면. 마지막은 0으로 되어 있는 것을 볼 수 있다. nil이 아니다.
s = s[:cap(s)]
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
1e9이라는 숫자를 본 적이 있는가?
 |
|---|
| 1e9에 대한 설명 |
A Tour of Go를 살펴보다 보니. 변수에 1e9을 대입한다.
응?
처음에는 뭔가 저정돤 메모리주소의 sample인가 싶었지만.
구글링 해 보니, 숫자를 선언하는 형식인것을 알게된다.
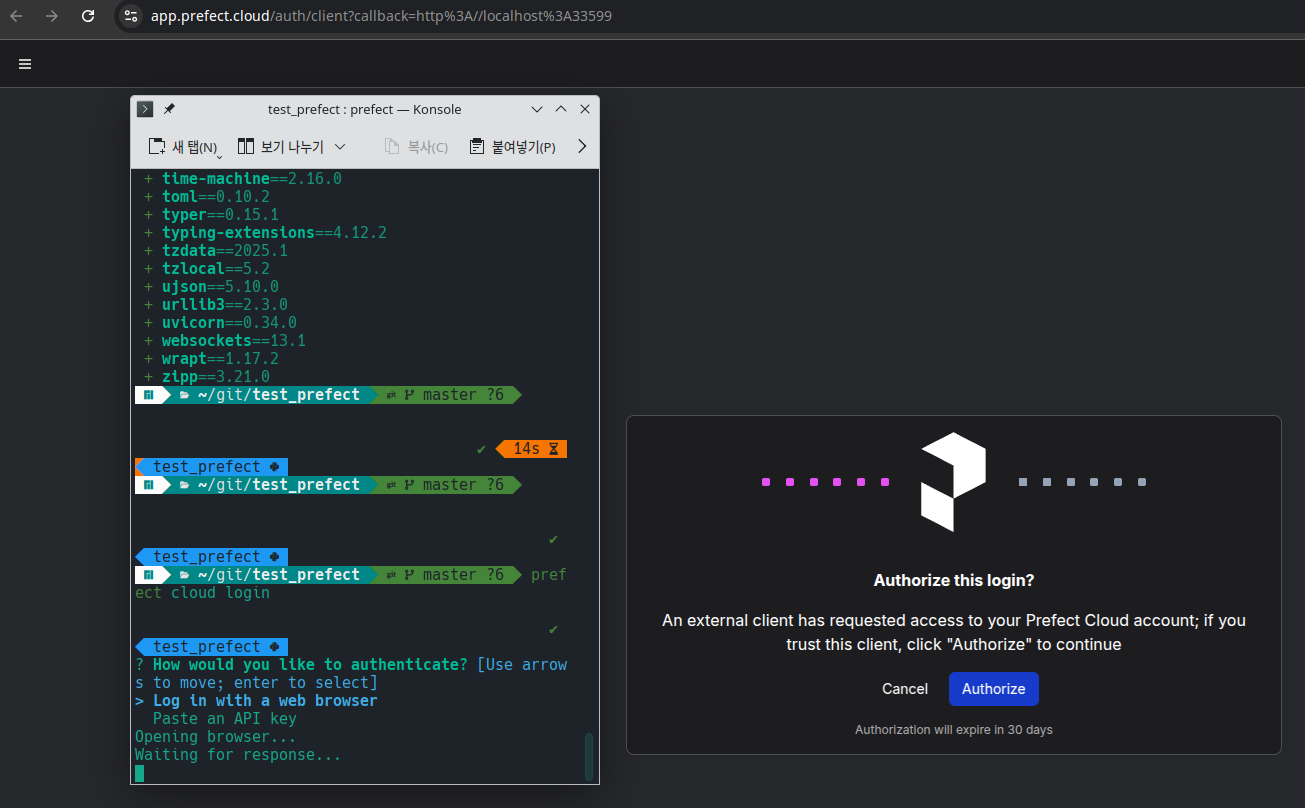
prefect cloud lgoin
 |
|---|
| Prefect 인증화면 |
Prefect를 살펴보기 위해서 Cloud에 sigin in 한 다음 따라하고 있었는데 말이다.
local cli에서 prefect module을 설치하고 cloud + login 파라메터로 실행을 하니, 진행중인 웹브라우저로 인증을 한다.
당연히 web을 통한 인터페이스만 제공되는 줄 알았는데, local 환경을 제공하는 것은 어떤의미일런지.
 |
|---|
| Prefect local deploy 화면 |
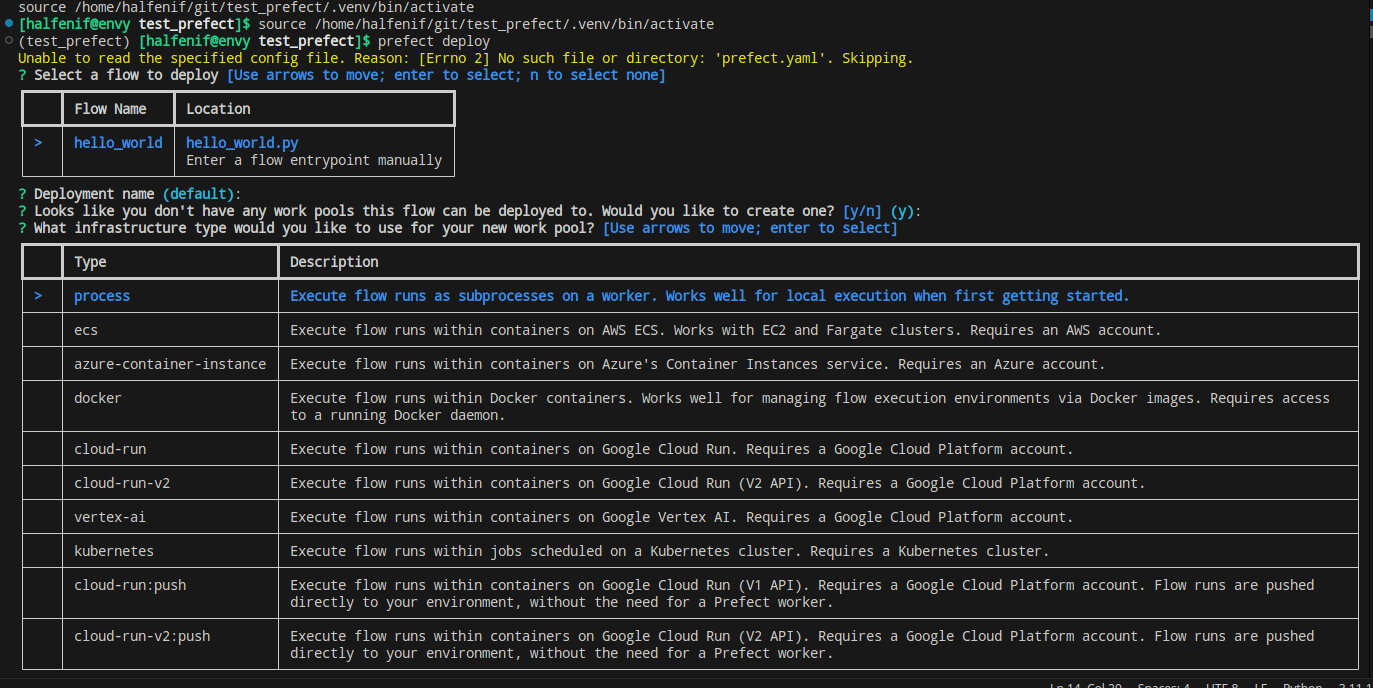
한참을 뒤지다가 local에서 server를 띄우고 deploy를 실행 해 본다.
이런 CLI에서 본격적으로 select하는 녀석은 오래간만이다.
star vs. snowflake
dbt를 보다가 보니 이런 저런 내용이 나오는데, 누군가 star schema에 대한 언근이 있어 찾다가 MS의 Understand star schema라는 페이지를 찾았다.
좀더 구체적인 비교를 찾아 질의 해 본다.
1. 구조 (Structure)
Star Schema
- 중앙에 하나의 팩트 테이블이 있고, 이를 둘러싼 다수의 디멘션 테이블로 구성됩니다.
- 디멘션 테이블은 비정규화된(flat) 형태로 설계되며, 각 디멘션이 별도의 테이블로 저장됩니다.
- 단순한 구조를 가지며 별 모양을 띱니다.
Snowflake Schema
- 팩트 테이블은 동일하지만, 디멘션 테이블이 정규화된(normalized) 형태로 설계됩니다.
- 디멘션 테이블이 하위 디멘션으로 분할되어 복잡한 트리 구조를 형성합니다.
- 눈송이(snowflake) 모양을 닮은 구조입니다.
2. 정규화 수준 (Normalization)
Star Schema
- 디멘션 테이블이 비정규화(denormalized) 되어 있습니다.
- 하나의 디멘션 테이블에 모든 속성이 포함되며, 중복 데이터가 있을 수 있습니다.
Snowflake Schema
- 디멘션 테이블이 정규화(normalized) 되어 있습니다.
- 중복 데이터를 제거하고 디멘션 속성을 여러 테이블로 나눕니다.
3. 복잡도 (Complexity)
Star Schema
- 구조가 단순하여 이해 및 유지 관리가 용이합니다.
- 쿼리가 간단하고 빠르게 실행됩니다.
- 데이터 웨어하우스 설계 초보자나 소규모 프로젝트에 적합합니다.
Snowflake Schema
- 구조가 복잡하며, 이해 및 유지 관리가 어려울 수 있습니다.
- 정규화로 인해 테이블 간 조인(join)이 많아 쿼리 성능이 떨어질 수 - 있습니다.
- 대규모 데이터 웨어하우스나 복잡한 데이터 관계를 다룰 때 유리합니다.
4. 성능 (Performance)
Star Schema
- 조인이 적어 쿼리 성능이 일반적으로 더 우수합니다.
- 디스크 공간 사용량은 더 많을 수 있습니다(중복 데이터 때문).
Snowflake Schema
- 정규화로 인해 조인(join) 작업이 많아 쿼리 성능이 저하될 수 있습니다.
- 디스크 공간 사용은 더 적습니다(중복 데이터가 제거됨).
5. 사용 사례 (Use Cases)
Star Schema
- 단순한 데이터 분석과 빠른 응답 시간이 필요한 경우.
- BI 도구나 OLAP(Online Analytical Processing)에서 자주 사용됨.
Snowflake Schema
- 데이터 중복을 최소화하고 정규화를 통해 데이터 무결성을 유지하려는 경우.
- 복잡한 데이터 관계를 명확히 표현해야 하는 경우.
비교 요약
| 특성 | Star Schema | Snowflake Schema |
|---|---|---|
| 구조 | 비정규화된 단순 구조 | 정규화된 복잡한 구조 |
| 데이터 중복 | 있음 | 없음 |
| 성능 | 쿼리 성능이 우수 | 조인으로 인해 성능 저하 가능 |
| 설계 복잡도 | 낮음 | 높음 |
| 디스크 공간 사용 | 더 많이 필요할 수 있음 | 더 적게 필요함 |
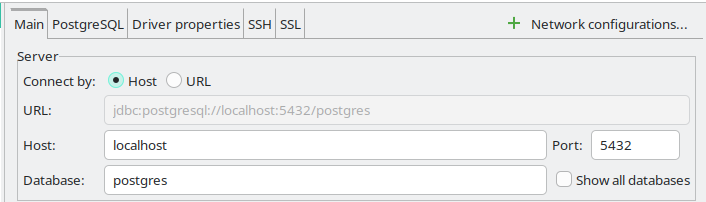
DBeaver + SSH Tunneling
 |
|---|
| SSH로 연결 할 때 IP는 local host이다. |
Oracle Cloud에서 메모리 부족 사태를 겪은 후 DEMO용 DBMS에 대해서 가급적이면 sqlite를 사용하려고 노력하고 있었다.
그런데, wiki.js라던지 FastAPI 공식 Template을 사용 해 보면서, 결국 DB는 postgresql로 넘어갔구나 하는 생각을 하고, 메모리를 얼마나 점유하는지 확인 해 보니, 그리 걱정 할 수준은 아니라고 판단해서 올려 놓기로 한다.
막상 container를 올려놓고 보니, 관리하는 것이 영 불편할것 같아, remote db에는 직접 접속하지 않겠다는 기존 생각을 고쳐먹고, ssh tunneling을 시도 해 보는데.
task-centric vs. asset-centric workflow
dagster의 교육과정을 살펴보고 있다가 task-centric과 asset-centric이라는 단어를 보게되었다.
예를 든 초컬릿 칩 쿠키를 만드는 과정에서 task중심은 [재료모으기, 재료섞기, 초컬릿칩 추가하기, 굽기]로 Task를 기술하고, 재료나 중간가공품(쿠키 도우와 같은)은 별도로 표시(주석정도?)하는 방식이고, asset은 [주재표, 부재료, 중간가공품]과 같이 재품의 각 상태를 주요하게 기술하고, 각 상태를 전이시키는 task는 주석 정도로 표시하는 방식이다.
이 얼마나 명확한 방법인가 싶어, 이제까지 이런 생각을 못했다니 싶다.
참고로 Data engineering에는 asset중심이 더 유리하다 한다.
- data lineage측면. (이걸 혈통이라고 번역하면 좀 이상하기는 한데. 적절하기도 하다.)에 대한 파악이 용이하다고 한다. 일리가 있다.
- asset의 재활용 측면.
- asset의 freshness측면. (이걸 선도라고 번역하면.) 데이터가 얼마나 신선한가? 의미있는 부분이다.
- debugging측면.
dagster를 보다가 보니까 dbt를 자연스럽게 보게 된다.
Console + 인식
 |
|---|
| pamac를 실행했는데, 왜 Chrome을? |
아침에 jq라는 녀석을 한 번 해 보려고 pamac에서 jq를 설치하려 했더니 Chrome을 갱신하고 있다.
Manjaro를 사용 한 지 거의 1년이 다 되어 가지만 아직도 apt에 비해 익숙하지 않은건 사실이고, apt에 비해 더 가벼운 느낌이라는 것도 사실이다.
왜 더 가벼운 느낌일까?
Manjaro를 처음 사용하기 시작하면서, pamac와 pacman에 대해 구분하지 않고 대충 구글링해서 나오는 것을 기계적으로 입력하던 버릇은 apt에서 기인 한 것이라 생각된다.
이 부분을 잘 살펴보면, 인식, 인지 그리고 내가 지금 하려고 하는 것을 향한 돌진에 그것이 걸림돌이 되지 않는다면 아무런 상관이 없는 Console에 뿌려지는 단어들이라는 생각이다.
Rust + String
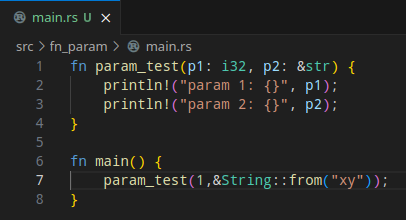 |
|---|
| Rust에서 문자를 파라미터로 넘기는 모습을 봐라 |
새해들어서 어떻게든 호기심을 유지하려고 한 해 동안 모아두었던 링크들을 정리하고, 하나씩 해 보고 있다.
Rust의 경우. 첫 번쩨 빌드하기 위한 소스의 구조를 toml에 기술해줘야 한다는 것은.. 뭔 그럴수 있다고 치자.
그 다음 파라미터를 좀 보면서 문자열을 넘기는 부분을 보다 아연실색한다.
그리고 좋다고 생각한다.
형식은 언제나 익숙해지기 마련이다. 생각을 잘 하면 매우 유용 할 것이고, 가변적인 상황을 전부 상정해서 어떻게 하려면.. 아마 방법이든 패턴이든 라이브러리든 있을 것으로 생각된다.
2025년 살펴 볼 목록들 (시작)
2024년 프로젝트 진행하느라 링크만 남겨뒀던 것들을 주워모아 본다.
지인
바닐라 프론트: 이병옥 대표가 드디어 릴리즈 했다.
ETL or Data Process
아래 4개가 도출되었음
airflow - 아직까지는 가장 범용적 a platform created by the community to programmatically author, schedule and monitor workflows
Prefect Cloud 버전을 테스트중. local은 찾아보고 있음.
Mage 홈페이지에 AI틱한 문구를 띄우고 있지만.
dagster - data pipeline oneline solution? “Data engineering doesn’t need to be a drag"라는데?
luigi - build complex pipelines of batch jobs 간단한 깃헙 페이지?