REST 응답에 meta data를 포함하는 것
 |
|---|
| rest 응답에 메타정보를 포함하는 방식 |
REST API 설계의 기본이라는 동영상을 보다보니, 데이터 이외에 메타정보를 포함하는 내용이 나온다.
REST를 구성하면서 한 번도 생각해 본적이 없는 것이라 살짝 당혹스럽다.
물론 차세대라고 불리는 SI 할 때는 응답전문에 복수의 배열이 포함될수 있음으로 배열명과 동일한 _변수를 반드시 선언하는 식으로 많이들 하긴 했었다만.
이것을 좀더 나이스한 메타정보로 어찌해 볼 생각은 왜 못했을까 싶다.
 |
|---|
| GET, POST의 용법에 대해서도 다시 생각한다 |
물론 기본은 기본이지만 나는 대부분 GET과 POST로 모든것을 다 처리하고 있었는데 말이다.
http에서 Cache-Control 설명
Cache-Control 설명
Cache-Control은 HTTP/1.1에서 도입된 표준 헤더로, 브라우저, 프록시 서버 등 다양한 캐시 주체가 리소스를 어떻게 저장하고 재사용할지 제어하는 역할을 합니다. 이 헤더는 요청(request)과 응답(response) 모두에서 사용되며, 웹 리소스의 캐싱 정책을 세밀하게 지정할 수 있습니다123.
주요 Cache-Control 지시어
- max-age=초
리소스가 캐시에 저장될 수 있는 최대 시간을 초 단위로 지정합니다. 예를 들어,
Cache-Control: max-age=120은 120초 동안 캐시가 유효함을 의미합니다145. - no-cache 캐시에 저장은 가능하지만, 실제로 사용하기 전에 반드시 원 서버에 유효성 검사를 해야 합니다. 즉, 매번 서버에 변경 여부를 확인합니다162.
- no-store 어떤 캐시에도 저장하지 않음을 의미합니다. 민감한 정보나 보안이 중요한 데이터에 주로 사용됩니다162.
- public 모든 캐시(브라우저, 프록시 등)에 저장할 수 있음을 나타냅니다. 인증이 필요한 응답도 캐시할 수 있게 허용합니다12.
- private 오직 개인 사용자(브라우저) 캐시에만 저장할 수 있고, 프록시와 같은 공유 캐시에는 저장하지 않습니다. 기본값이 private인 경우가 많습니다12.
- s-maxage=초 프록시(공유 캐시)에만 적용되는 max-age 값입니다. 개인 캐시에는 영향을 주지 않습니다1.
동작 예시
SAML이란?
SAML이란?
**SAML(Security Assertion Markup Language)**은 XML 기반의 개방형 표준 프로토콜로, 서로 다른 시스템 간에 사용자 인증 및 권한 부여 정보를 안전하게 교환할 수 있도록 설계되었습니다123. SAML은 주로 기업 환경에서 싱글 사인온(SSO, Single Sign-On) 구현에 널리 사용되며, 사용자가 한 번만 로그인하면 다양한 웹 애플리케이션이나 서비스에 반복 로그인 없이 접근할 수 있게 해줍니다456.
주요 구성 요소
- ID 공급자(IdP, Identity Provider): 사용자의 신원을 인증하고, 인증 정보를 서비스 공급자에게 전달하는 역할을 합니다126.
- 서비스 공급자(SP, Service Provider): 사용자가 접근하려는 웹 애플리케이션이나 서비스로, IdP로부터 받은 인증 정보를 바탕으로 접근 권한을 부여합니다126.
동작 원리
- 사용자가 서비스 공급자(SP)에 접근을 시도합니다.
- SP는 사용자를 ID 공급자(IdP)로 리디렉션하여 인증을 요청합니다.
- 사용자가 IdP에서 로그인하면, IdP는 인증된 사용자 정보를 SAML 어설션(assertion) 형태의 XML 문서로 SP에 전달합니다7.
- SP는 이 어설션을 검증한 후 사용자의 접근을 허가합니다891.
이 과정에서 사용자는 여러 서비스에 반복적으로 로그인할 필요 없이 한 번의 인증만으로 다양한 리소스에 접근할 수 있습니다.
go 바이너리에 frontend를 포함시키는 방법
filebrowser를 fork해서 뭔가 수정을 좀 해보려고 하는데, 포함된 front를 막연하게 build하고 go runtime에서 해당 dist 폴더를 참조하는 줄 알았더니, go 바이너리에 아예 포함시키나 보다.
[filebrowser_tag_editor]$ mv frontend frontend.back
[filebrowser_tag_editor]$ rm filebrowser
[filebrowser_tag_editor]$ go build
cmd/root.go:26:2: no required module provides package github.com/filebrowser/filebrowser/v2/frontend; to add it:
go get github.com/filebrowser/filebrowser/v2/frontend
혹시나 하는 마음에 frontend를 아예 없애버리고 buid를 했더니, 정확하게 메시지를 보여준다.
rocky + SELinux
setenforce 0
restorecon -v /usr/local/toy_redis_to_posgres/toy_redis_to_postgres
setenforce 1
minikube + podman
발단은 OpenFaaS라는 녀석을 써볼까 싶어 시작 한 것인데. 이 녀석이 k8s를 필요로 하고, 두 가지 방법이 권장된다.
k8s 혹은 docker swarm.
나는 podman에 치중하고 있음으로, 당연 swarm이 있을리 없고, 단일 컴퓨트를 사용하고 있기 때문에, k8s도 가지고 있지 않다.
궁여지책으로 minikube를 생각했더니, 이론상으로는 되는데, 현실적인 문제에 직면하는 것 같다.
Minikube에서 “The ‘podman’ driver should not be used with root privileges"라는 메시지가 나타나는 이유는, Podman 드라이버가 root 권한이 아닌 일반 사용자(rootless)로 실행되는 것이 보안상 권장되기 때문입니다. Podman은 기본적으로 rootless(비루트) 컨테이너 실행을 지향하며, root 권한으로 실행할 경우 보안 위험이 커질 수 있습니다.
Firebase 특정 host에 deploy
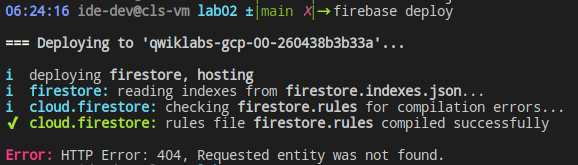 |
|---|
| 뭔가 빠져있다는 메시지 |
GCP스터디를 진행하다 보니 deploy가 안 된다.
처음에는 단순한 bucket인줄 알았는데.
firebase hosting:sites:create [사이트 ID]
이런 형태로 만들어줘야 하는 것이었다.
물론.. default에 배포한다면 안 해도 되는 것이기는 하다.
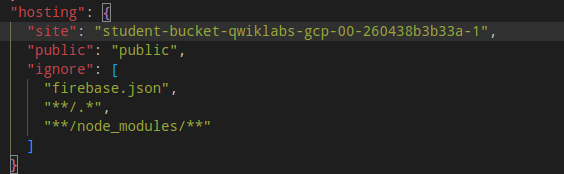 |
|---|
| firebase.json |
추가로 firebase.json은 왜 editing이 안 되는 것이냐? console에서 nano로 수정하고 있다.
goLang으로 만들어진 webhook과 gitHub 연결
jekyll을 hugo로 바꾸는 목적이 “절차의 간단함"임으로 push하는 동시에 blog가 생성되도록 하는 방법을 찾아본다.
BigQueryML에서 TRANSFORM
BigQueryML에서 TRANSFORM은 모델 학습 전에 데이터 전처리를 선언적으로 지정할 수 있는 기능입니다. 이를 통해 훈련/예측 시 일관된 전처리 파이프라인을 적용할 수 있으며, 특히 파이프라인 재사용이나 자동 특성 엔지니어링에 유용합니다.
✅ 기본 개념
BigQueryML의 TRANSFORM 구문은 CREATE MODEL 문에서 사용되며, 주로 다음과 같이 구성됩니다:
CREATE MODEL project.dataset.model_name
TRANSFORM (
-- 변환 정의
)
OPTIONS (...) AS
SELECT ...
🔧 예제: 범주형 인코딩 + 스케일링
CREATE OR REPLACE MODEL my_dataset.my_model
TRANSFORM (
one_hot_encoded_country AS
one_hot_encode(country),
scaled_age AS
standard_scaler(age)
)
OPTIONS (
model_type = 'logistic_reg',
input_label_cols = ['label']
) AS
SELECT
country,
age,
label
FROM
my_dataset.training_data;
one_hot_encode(country): 범주형 변수 인코딩standard_scaler(age): 평균 0, 표준편차 1로 정규화TRANSFORM블록에서 정의된 컬럼은 아래SELECT의 컬럼을 전처리하여 학습에 사용됨
🧠 지원되는 주요 변환 함수
| 함수 | 설명 |
|---|---|
one_hot_encode(col) |
범주형 변수 → 원-핫 인코딩 |
log(col) |
로그 변환 |
normalize(col) |
0~1 정규화 |
standard_scaler(col) |
표준화 (Z-score) |
bucketize(col, boundaries) |
수치형 변수 → 구간화 |
clip(col, min, max) |
값 제한 |
cast(col AS TYPE) |
형변환 |
📌 참고 사항
TRANSFORM은 모델 정의 내부에서만 사용 가능합니다.SELECT쿼리에서는 사용 불가합니다.TRANSFORM블록의 출력 컬럼명은 모델이 학습에 사용하는 특성명입니다.SELECT절에서는 원본 컬럼을 제공해야 합니다. (전처리는TRANSFORM안에서 수행됨)
🔍 예제: 날짜 파싱 및 로그 변환
CREATE OR REPLACE MODEL my_dataset.sales_model
TRANSFORM (
log_price AS log(price),
day_of_week AS EXTRACT(DAYOFWEEK FROM DATE(timestamp))
)
OPTIONS (
model_type = 'linear_reg',
input_label_cols = ['sales']
) AS
SELECT
price,
timestamp,
sales
FROM
my_dataset.sales_data;
필요하다면 TRANSFORM 없이도 SQL로 사전 전처리를 해서 CREATE MODEL에 넘길 수 있지만, TRANSFORM을 쓰면 학습-예측 간 일관성이 보장됩니다.
podman 자동 재시작
주) 이렇게 안 해도
Podman + docker-compose (또는 podman-compose) 환경에서 OS 재부팅 후 컨테이너 자동 시작을 설정하려면 Docker처럼 기본적으로 restart: always만으로는 자동 시작되지 않으며, Podman의 systemd 통합을 사용해야 합니다.
✅ 방법 1: podman generate systemd로 systemd 유닛 생성
-
컨테이너를 먼저 실행
podman run -d --name my-app-container my-image
-
systemd 서비스 유닛 파일 생성
podman generate systemd --name my-app-container --files --restart-policy=always
이 명령은 현재 디렉토리에 .service 파일을 생성합니다. 예를 들어:
container-my-app-container.service
-
systemd 디렉토리로 복사
sudo cp container-my-app-container.service /etc/systemd/system/
-
서비스 등록 및 자동 시작 설정
sudo systemctl daemon-reexec
sudo systemctl enable --now container-my-app-container.service
✅ 방법 2: Podman pod을 사용하고 pod 기준으로 systemd 설정
Podman pod을 사용할 경우에도 동일하게 podman generate systemd --name mypod로 유닛을 만들고 등록할 수 있습니다.