Below you will find pages that utilize the taxonomy term “Config”
i2cdetect + RAM Temp.

(유튭을 틀면 가끔씩 죽는 내 노특북을)(절간처럼 조용한)사무실에서 사용하고 있기에 갑자기 팬 소리가 신경쓰여 무엇인 문제인지 찾아보기 시작.
결론은
- sensors에 RAM 온도가 없음
- jc42 모듈을 로드해야 한다고 해서 해 봤으나 여전히 없음
- i2c-tools를 설치하고 봤더니, 온도 센서가 없는 RAM임
- 그런 RAM을 시금치라고 부른다고 함.
게시판에서 시금치 시금치 해서 뭔가 싶었더니 센서가 없는 대중적인 사양이었나 봄.
ps - 온도센서가 있다면 “RAM 온도 센서(jc42)는 규격상 반드시 18에서 1f 사이의 주소에 나타나야 합니다.“라고 한다.
syncthing chnage binding port
이런저런 사정으로 OMV에 syncthing을 설치하게 되었는데, WebUI에 해당하는 8384 port로 외부에서 접속이 안 되는 현상.
처음에는 OMV의 방화벽인가 생각했으나, 설정에서 127.0.0.1에 바인딩되어 그런 현상이.
가끔씩 이런 적이 있는거 보면..
<gui enabled="true" tls="false">
<address>0.0.0.0:8384</address>
</gui>
omarchy + podman + /dev/net/tun
1,000만건 테스트 할 일이 있어 pentaho로 돌렸더니 점점 느려지는 문제를 보다가 apache nifi를 한 번 써보기로 하고 oracle-xe container를 올리는데 처음 보는 메시지가 출력된다.
Failed to open() /dev/net/tun: No such device
- tun을 찾아보면 물리장치와 가상장치를 연결하는 쪽으로 대충 나온다
- 처음에는 podman쪽에서 뭔가 rootless관련 설정이 바뀌나 싶었으나
- 무슨 이유인지는 모르겠으나 omarchy에서 tun 모듈이 설치가 안 되어 있었다.
lsmod | grep tun #확인
sudo pacman -S linux
linux 기본 모듈을 재 설치 해 주고 나니 올라온다.
omarchy + walker + elephant restore
omarchy는 현재 사용하고 있는 archy linux로 만족하고 있다.
어느날 update를 했더니 Win + Alt + Space로 실행되는 명령이 오류를 출력한다.
좀 찾아보니 walker와 elephant라는 녀석들인데.. 구체적으로 무엇인지 찾아보지는 않았다.
# 어떤 재설치를 하고 리부팅까지 했으나 적용되지 않았었다.
# 내 경우에는 다음 명령이 주효 했다.
omarchy-refresh-walker
현재 특정 port를 점유중인 프로세스의 파일 찾기
hugo가 뭔가 망가져서 복구를 하다 보니 서버의 blog 컨테츠가 전부 날라간 상태
이유는 os 패치하면서 먼가 건드려진 모양이지만. 그게 중요한건 아니고.
Github에 commit되면 webhook으로 hugo build를 하도록 해 놓은 기억은 있는데, 아무리 찾아도 어떤 프로세스가 받는지 못찾는 상황이었다.
# 특정 port의 프로세스 찾기
sudo ss -ltnp | grep :8080
# 특정 프로세스의 실행 파일 찾기 예, 1207 프로세스
ls -l /proc/1207/exe
batcat + 모던리눅스 도구
tail -f /var/log/pacman.log | bat --paging=never -l log
이 문장을 보며 생각한다. 터미널에서 로그가 총 천연색으로 tail되는 모습을.
omachy + korean
놀라운 점은 리부팅이나 재로그인이 필요없았다는 점이고
sudo pacman -S fcitx5 fcitx5-qt fcitx5-gtk fcitx5-configtool
sudo pacman -S fcitx5-hangul
#.bashrc
GTK_IM_MODULE=fcitx5
QT_IM_MODULE=fcitx5
XMODIFIERS="@im=fcitx5"
fcitx5-configtool
더 놀라운 점은.. 한글 입력시 첫 자음이 마음데로 찍히는 경우가 있다는 점이다.
omarchy + rotate monitor 90
hyprctl monitors # Check Monitor
#hyprland.conf
monitor=HDMI-A-1,preferred,auto,1.666667,transform,1
update-grub + 부적절한 서식 문자
GRUB 설정 파일 만드는 중 ...
테마 찾음: /usr/share/grub/themes/manjaro/theme.txt
리눅스 이미지 발견: /boot/vmlinuz-6.6-x86_64
초기 램디스크 이미지 발견: /boot/amd-ucode.img /boot/initramfs-6.6-x86_64.img
Found initrd fallback image: /boot/initramfs-6.6-x86_64-fallback.img
경고: 기타 부팅 분할 영역을 찾는 과정에서 os-prober를 실행했습니다.
출력 내용은 부팅 바이너리 검색 및 새 부팅 항목 만들기 과정에 활용했습니다.
/usr/share/grub/grub-mkconfig_lib: 행 263번: printf: `$': 부적절한 서식 문자
찾은내용: https://jimnong.tistory.com/1611
sudo LC_ALL=C update-grub
omarchy + korea + fcitx5
누군가 omarchy에 대한 이야야기를 하고 있어서 잘쓰고 있는 manjaro를 지우고 노트북에 설치를 했었더랬다.
익숙하지 않은 이걸 뭐라고 부를지 모르겠지만 타일형태의 UI는 어찌어찌 적응을 한다고 하지만 한글이 설치되지 않는건 좀 그랬다.
늘 하던데로 nimf를 시도했으나, 컴파일에서 실패.
ibus는 익숙하지도 않지만 몇 번 시도해보지도 않았다.
우측 상단에 있는 키보드 아이콘에서 fcitx5를 발견하고는 관련 포스팅을 좀 찾아본뒤 설정 해 본다.
이 배포판인지 설정인지에 해당하는 녀석은 fctix5가 잘된다는 느낌이다.
/dev/tpm0 issue on archlinux
sudo systemctl mask dev-tpmrm0.device
sudo systemctl mask tpm2.target
in my case. tpm2.target effect.
anduin linux + vscode
Manjaro를 주력으로 매우 만족하며 사용하고 있었지만, HP Envy + AMD가 자꾸만 프리징되는 현상으로 고민만 하다가 우연한 기회에 하찬게 보던 Ubnutu 기반의 Anduin을 설치하고 테스트 해 보는데, 프리징이 걸리기는 하나 좀 기다리면 살아나기는 한다.
VSCode를 설치했는데, 당연하던 cli에서 code 명령이 먹지 않는다. VSCode market이 살짝 신경쓰였는지 MS 배포판만 사용하고 싶어서인지 store에서만 설치했는데, Ubuntu에서는 Flatpak으로 설치되나 보다. 좀 찾아보고 설정한다.
echo 'alias code="flatpak run com.visualstudio.code"' >> ~/.bashrc
source ~/.bashrc
이 설치된 녀석의 기본적인 환경이 좀 그렇다. 사용하면서 얼마나 고쳐야 할런지는.
Pentaho ETL
최근 Jasper 유사한 ETL도구가 필요한 상황이 되어 찾아보다 발견한 Pentaho Data Integration을 테스트 하고 있다.
Jasper보다 나중에 만들어졌고 나름 깔끔하다.
duckdb + excel
SELECT current_setting('extension_directory');
SELECT * FROM pragma_version();
SELECT duckdb_version();
# extension 상태를 볼 수 있다.
SELECT * FROM duckdb_extensions();
INSTALL 'excel';
LOAD 'excel';
select * from read_xlsx('file_example_XLSX_5000.xlsx');
select * from read_excel('file_example_XLSX_5000.xlsx');
Excel을 읽어서 sqlite에 넣으려다 왠지 있을것같아 찾아보니 있다.
duckdb에 excel을(csv가 아니다) 직접 읽을수 있는 방법을 찾아보니 있다.
다만, 이 녀석 여러가지 버전관련 설정을 타는지, duckdb_version() 명령은 안 되고, pragma_version()으로 확인 했을 때 v1.3.0에서 read_xlsx() 명령으로 작동하는 것을 확인한다.
즉, 자신의 상황에따라 이것 저것 점검 할 것이 많다는 뜻일수있다.
WSL에서 방화벽 열기
New-NetFirewallRule -DisplayName "WSL" -Direction Inbound -InterfaceAlias "vEthernet (WSL)" -Action Allow
New-NetFirewallRule -DisplayName "WSL2-MySQL" -Direction Inbound -LocalPort 3306 -Action Allow -Protocol TCP
WSL2에 설치된 서비스가 Windows에서 접속되지 않는 현상 점검 방법
WSL2(Windows Subsystem for Linux 2)에서 실행 중인 웹 서버, 데이터베이스 등 리눅스 서비스가 Windows(호스트)에서 접속되지 않을 때 점검해야 할 주요 항목과 해결 방법을 정리합니다.
1. 네트워크 구조 이해
- WSL1은 Windows와 네트워크를 공유(로컬호스트 사용)하지만,
- WSL2는 NAT 기반 가상 네트워크를 사용하여 별도의 내부 IP를 가집니다. 이 때문에 WSL2에서 실행한 서비스는 기본적으로 WSL2 내부 IP에서만 접근 가능하며, Windows에서 바로 접근이 안 될 수 있습니다123.
2. 서비스 바인딩 주소 확인
- 리눅스 서비스(예: 웹 서버)가
127.0.0.1(localhost)에만 바인딩되어 있으면 WSL2 내부에서만 접근 가능합니다. - 반드시 0.0.0.0 또는 WSL2의 내부 IP로 바인딩해야 Windows에서 접근할 수 있습니다.
예시 (Flask):
Test-NetConnection
Test-NetConnection -ComputerName localhost -Port 31143
어쩔수 없이 Win10을 사용하게되면서 PowerShell을 조금씩 써보고있다.
Win 시계가 자꾸만 틀림.
시스템을 설치하고 Window로 부팅하는 경우 시간이 자꾸 틀려서(==동기화가 안 되어서) MS가 다되었다 생각하고 있었는데 말이다.
오늘 몇 달만에 Window로 부팅을 했더니, 시간이 꼭 UTC라는 느낌이 들어 분을 보니 동일하다.
윈도우와 리눅스 듀얼부트 환경 대부분의 리눅스 배포판은 하드웨어(메인보드) 시계를 UTC로 저장하는 반면, 윈도우는 기본적으로 하드웨어 시계를 로컬 타임(한국 기준 KST 등)으로 간주합니다. 이로 인해 두 운영체제를 번갈아 부팅할 때 시간이 맞지 않거나, 윈도우에서 시간이 UTC 기준으로 표시되는 문제가 발생할 수 있습니다
그렇다고 합니다. 딱히 수정할 생각은 없다.
go 바이너리에 frontend를 포함시키는 방법
filebrowser를 fork해서 뭔가 수정을 좀 해보려고 하는데, 포함된 front를 막연하게 build하고 go runtime에서 해당 dist 폴더를 참조하는 줄 알았더니, go 바이너리에 아예 포함시키나 보다.
[filebrowser_tag_editor]$ mv frontend frontend.back
[filebrowser_tag_editor]$ rm filebrowser
[filebrowser_tag_editor]$ go build
cmd/root.go:26:2: no required module provides package github.com/filebrowser/filebrowser/v2/frontend; to add it:
go get github.com/filebrowser/filebrowser/v2/frontend
혹시나 하는 마음에 frontend를 아예 없애버리고 buid를 했더니, 정확하게 메시지를 보여준다.
rocky + SELinux
setenforce 0
restorecon -v /usr/local/toy_redis_to_posgres/toy_redis_to_postgres
setenforce 1
minikube + podman
발단은 OpenFaaS라는 녀석을 써볼까 싶어 시작 한 것인데. 이 녀석이 k8s를 필요로 하고, 두 가지 방법이 권장된다.
k8s 혹은 docker swarm.
나는 podman에 치중하고 있음으로, 당연 swarm이 있을리 없고, 단일 컴퓨트를 사용하고 있기 때문에, k8s도 가지고 있지 않다.
궁여지책으로 minikube를 생각했더니, 이론상으로는 되는데, 현실적인 문제에 직면하는 것 같다.
Minikube에서 “The ‘podman’ driver should not be used with root privileges"라는 메시지가 나타나는 이유는, Podman 드라이버가 root 권한이 아닌 일반 사용자(rootless)로 실행되는 것이 보안상 권장되기 때문입니다. Podman은 기본적으로 rootless(비루트) 컨테이너 실행을 지향하며, root 권한으로 실행할 경우 보안 위험이 커질 수 있습니다.
Firebase 특정 host에 deploy
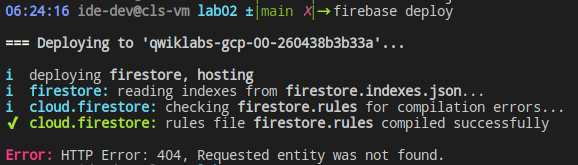 |
|---|
| 뭔가 빠져있다는 메시지 |
GCP스터디를 진행하다 보니 deploy가 안 된다.
처음에는 단순한 bucket인줄 알았는데.
firebase hosting:sites:create [사이트 ID]
이런 형태로 만들어줘야 하는 것이었다.
물론.. default에 배포한다면 안 해도 되는 것이기는 하다.
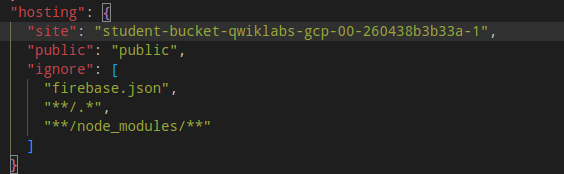 |
|---|
| firebase.json |
추가로 firebase.json은 왜 editing이 안 되는 것이냐? console에서 nano로 수정하고 있다.
goLang으로 만들어진 webhook과 gitHub 연결
jekyll을 hugo로 바꾸는 목적이 “절차의 간단함"임으로 push하는 동시에 blog가 생성되도록 하는 방법을 찾아본다.
podman 자동 재시작
주) 이렇게 안 해도
Podman + docker-compose (또는 podman-compose) 환경에서 OS 재부팅 후 컨테이너 자동 시작을 설정하려면 Docker처럼 기본적으로 restart: always만으로는 자동 시작되지 않으며, Podman의 systemd 통합을 사용해야 합니다.
✅ 방법 1: podman generate systemd로 systemd 유닛 생성
-
컨테이너를 먼저 실행
podman run -d --name my-app-container my-image
-
systemd 서비스 유닛 파일 생성
podman generate systemd --name my-app-container --files --restart-policy=always
이 명령은 현재 디렉토리에 .service 파일을 생성합니다. 예를 들어:
container-my-app-container.service
-
systemd 디렉토리로 복사
sudo cp container-my-app-container.service /etc/systemd/system/
-
서비스 등록 및 자동 시작 설정
sudo systemctl daemon-reexec
sudo systemctl enable --now container-my-app-container.service
✅ 방법 2: Podman pod을 사용하고 pod 기준으로 systemd 설정
Podman pod을 사용할 경우에도 동일하게 podman generate systemd --name mypod로 유닛을 만들고 등록할 수 있습니다.
Apache Nifi
Nifi를 설치하고
- 기본은 https 접속임 conf/nifi.properties
- 기본은 single user 접속임. 사용자 설정가이드
- 사용자 비번은 12자리 이상이며 설정했으면 한 번 리스타트 해야 적용됨.
GCP + GKE
gcloud config set project
gcloud config set compute/region
gcloud config set compute/zone
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
gcloud container clusters create fancy-prod-268 --num-nodes 3
gcloud compute instances list
gcloud services enable cloudbuild.googleapis.com
# build
cd ~/monolith-to-microservices/monolith
gcloud builds submit --tag gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-monolith-220:1.0.0 .
# deploy
kubectl create deployment fancy-monolith-220 --image=gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-monolith-220:1.0.0
# check
kubectl get all
# Show pods
kubectl get pods
# Show deployments
kubectl get deployments
# Show replica sets
kubectl get rs
#You can also combine them
kubectl get pods,deployments
kubectl get services
# delete
kubectl delete pod/<POD_NAME>
# expose
kubectl expose deployment fancy-monolith-220 --type=LoadBalancer --port 80 --target-port 8080
# Accessing the service
kubectl get service
~/monolith-to-microservices/microservices/src/orders
gcloud builds submit --tag gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-orders-430:1.0.0 .
kubectl create deployment fancy-orders-430 --image=gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-orders-430:1.0.0
kubectl expose deployment fancy-orders-430 --type=LoadBalancer --port 80 --target-port 8081
~/monolith-to-microservices/microservices/src/products
gcloud builds submit --tag gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-products-721:1.0.0 .
kubectl delete deployment fancy-products-721
kubectl create deployment fancy-products-721 --image=gcr.io/${GOOGLE_CLOUD_PROJECT}/products-721:1.0.0
kubectl expose deployment fancy-products-721 --type=LoadBalancer --port 80 --target-port 8082
~/monolith-to-microservices/microservices/src/frontend
gcloud builds submit --tag gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-frontend-189:1.0.0 .
kubectl create deployment fancy-frontend-189 --image=gcr.io/${GOOGLE_CLOUD_PROJECT}/fancy-frontend-189:1.0.0
kubectl expose deployment fancy-frontend-189 --type=LoadBalancer --port 80 --target-port 8080
------------------
# scale
kubectl scale deployment monolith --replicas=3
kubectl get all
# Make changes to the website
gcloud builds submit --tag gcr.io/${GOOGLE_CLOUD_PROJECT}/monolith:2.0.0 .
# Update website with zero downtime
kubectl set image deployment/monolith monolith=gcr.io/${GOOGLE_CLOUD_PROJECT}/monolith:2.0.0
kubectl get pods
# delete
# Delete the container image for version 1.0.0 of the monolith
gcloud container images delete gcr.io/${GOOGLE_CLOUD_PROJECT}/monolith:1.0.0 --quiet
# Delete the container image for version 2.0.0 of the monolith
gcloud container images delete gcr.io/${GOOGLE_CLOUD_PROJECT}/monolith:2.0.0 --quiet
# The following command will take all source archives from all builds and delete them from cloud storage
# Run this command to print all sources:
# gcloud builds list | awk 'NR > 1 {print $4}'
gcloud builds list | grep 'SOURCE' | cut -d ' ' -f2 | while read line; do gsutil rm $line; done
kubectl delete service monolith
kubectl delete deployment monolith
gcloud container clusters delete fancy-cluster lab region
GCP Website Make
# App Build & Docker Deploy
# artifactregistry Repository
gcloud auth configure-docker us-east1-docker.pkg.dev
gcloud services enable artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com
# Submit
gcloud builds submit --tag us-east1-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/monolith-demo/monolith:1.0.0
# Cloud Build 에서 진행상태 볼 수 있다.
# Deploy Container
gcloud run deploy monolith --image us-east1-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/monolith-demo/monolith:1.0.0 --region us-east1
# check
gcloud run services list
# Create new revision with lower concurrency ??
gcloud run deploy monolith --image us-east1-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/monolith-demo/monolith:1.0.0 --region us-east1 --concurrency 1
gcloud run deploy monolith --image us-east1-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/monolith-demo/monolith:1.0.0 --region us-east1 --concurrency 80
# Cloud Run에서 확인가능
# node module 지우고 올리기
cd ~
rm -rf monolith-to-microservices/*/node_modules
gsutil -m cp -r monolith-to-microservices gs://fancy-store-$DEVSHELL_PROJECT_ID/
# 인스턴스 만들기
gcloud compute instances create backend \
--zone=$ZONE \
--machine-type=e2-standard-2 \
--tags=backend \
--metadata=startup-script-url=https://storage.googleapis.com/fancy-store-$DEVSHELL_PROJECT_ID/startup-script.sh
# ip확인
gcloud compute instances list
# Firewall. 적용하고 3분 기다려야 된다.
gcloud compute firewall-rules create fw-fe \
--allow tcp:8080 \
--target-tags=frontend
gcloud compute firewall-rules create fw-be \
--allow tcp:8081-8082 \
--target-tags=backend
# 끄고
gcloud compute instances stop frontend --zone=$ZONE
gcloud compute instances stop backend --zone=$ZONE
# 인스턴스를 템플릿으로 만든다.
gcloud compute instance-templates create fancy-fe \
--source-instance-zone=$ZONE \
--source-instance=frontend
gcloud compute instance-templates create fancy-be \
--source-instance-zone=$ZONE \
--source-instance=backend
gcloud compute instance-templates list
# 기존의 것을 지우고
gcloud compute instances delete backend --zone=$ZONE
# managed 로 다시 만든다
gcloud compute instance-groups managed create fancy-fe-mig \
--zone=$ZONE \
--base-instance-name fancy-fe \
--size 2 \
--template fancy-fe
gcloud compute instance-groups managed create fancy-be-mig \
--zone=$ZONE \
--base-instance-name fancy-be \
--size 2 \
--template fancy-be
# set-named-port라는 명령이 있네
gcloud compute instance-groups set-named-ports fancy-fe-mig \
--zone=$ZONE \
--named-ports frontend:8080
gcloud compute instance-groups set-named-ports fancy-be-mig \
--zone=$ZONE \
--named-ports orders:8081,products:8082
# 핼스체크 추가
gcloud compute health-checks create http fancy-fe-hc \
--port 8080 \
--check-interval 30s \
--healthy-threshold 1 \
--timeout 10s \
--unhealthy-threshold 3
gcloud compute health-checks create http fancy-be-hc \
--port 8081 \
--request-path=/api/orders \
--check-interval 30s \
--healthy-threshold 1 \
--timeout 10s \
--unhealthy-threshold 3
gcloud compute firewall-rules create allow-health-check \
--allow tcp:8080-8081 \
--source-ranges 130.211.0.0/22,35.191.0.0/16 \
--network default
# 헬스체크한 뒤 업데이트 해야 하나 보다
gcloud compute instance-groups managed update fancy-fe-mig \
--zone=$ZONE \
--health-check fancy-fe-hc \
--initial-delay 300
gcloud compute instance-groups managed update fancy-be-mig \
--zone=$ZONE \
--health-check fancy-be-hc \
--initial-delay 300
# Create load balancers
gcloud compute http-health-checks create fancy-fe-frontend-hc \
--request-path / \
--port 8080
gcloud compute http-health-checks create fancy-be-orders-hc \
--request-path /api/orders \
--port 8081
gcloud compute http-health-checks create fancy-be-products-hc \
--request-path /api/products \
--port 8082
# 엥?
# Note: These health checks are for the load balancer, and only handle directing traffic from the load balancer; they do not cause the managed instance groups to recreate instances.
gcloud compute backend-services create fancy-fe-frontend \
--http-health-checks fancy-fe-frontend-hc \
--port-name frontend \
--global
gcloud compute backend-services create fancy-be-orders \
--http-health-checks fancy-be-orders-hc \
--port-name orders \
--global
gcloud compute backend-services create fancy-be-products \
--http-health-checks fancy-be-products-hc \
--port-name products \
--global
# 로드 밸런서도?... 이렇게 복잡하게 해야하는건가? 보다.
gcloud compute backend-services add-backend fancy-fe-frontend \
--instance-group-zone=$ZONE \
--instance-group fancy-fe-mig \
--global
gcloud compute backend-services add-backend fancy-be-orders \
--instance-group-zone=$ZONE \
--instance-group fancy-be-mig \
--global
gcloud compute backend-services add-backend fancy-be-products \
--instance-group-zone=$ZONE \
--instance-group fancy-be-mig \
--global
# Create a URL map. 악!
gcloud compute url-maps create fancy-map \
--default-service fancy-fe-frontend
# 아... 이건 Nginx에서 라우팅 하는 것 처럼 보인다.
#Create a path matcher to allow the /api/orders and /api/products paths to route to their respective services:
gcloud compute url-maps add-path-matcher fancy-map \
--default-service fancy-fe-frontend \
--path-matcher-name orders \
--path-rules "/api/orders=fancy-be-orders,/api/products=fancy-be-products"
# 맵을 만들고... 용어가 달라서 그렇군.
# Create the proxy which ties to the URL map:
gcloud compute target-http-proxies create fancy-proxy \
--url-map fancy-map
# 포워딩
# Create a global forwarding rule that ties a public IP address and port to the proxy:
gcloud compute forwarding-rules create fancy-http-rule \
--global \
--target-http-proxy fancy-proxy \
--ports 80
# Find the IP address for the Load Balancer:
gcloud compute forwarding-rules list --global
# ip가 바뀌었을테네.. .env 파일 바꿔준다. 음.. 이건 좀.
# 다시 빌드하고 다시 배포 한다.... 음.. .env를 안쓰면 되나? 거참.
cd ~/monolith-to-microservices/react-app
npm install && npm run-script build
cd ~
rm -rf monolith-to-microservices/*/node_modules
gsutil -m cp -r monolith-to-microservices gs://fancy-store-$DEVSHELL_PROJECT_ID/
gcloud compute instance-groups managed rolling-action replace fancy-fe-mig \
--zone=$ZONE \
--max-unavailable 100%
# 체크
watch -n 2 gcloud compute backend-services get-health fancy-fe-frontend --global
# 스케일 변경
gcloud compute instance-groups managed set-autoscaling \
fancy-fe-mig \
--zone=$ZONE \
--max-num-replicas 2 \
--target-load-balancing-utilization 0.60
gcloud compute instance-groups managed set-autoscaling \
fancy-be-mig \
--zone=$ZONE \
--max-num-replicas 2 \
--target-load-balancing-utilization 0.60
# CDN...은 어떻게 설정되는지?
# Enable content delivery network
gcloud compute backend-services update fancy-fe-frontend \
--enable-cdn --global
# 인스턴스 사이즈 변경
gcloud compute instances set-machine-type frontend \
--zone=$ZONE \
--machine-type e2-small
gcloud compute instance-templates create fancy-fe-new \
--region=$REGION \
--source-instance=frontend \
--source-instance-zone=$ZONE
gcloud compute instance-groups managed rolling-action start-update fancy-fe-mig \
--zone=$ZONE \
--version template=fancy-fe-new
# 와치? 3분 정도 걸린다고 함.
watch -n 2 gcloud compute instance-groups managed list-instances fancy-fe-mig \
--zone=$ZONE
gcloud compute instances describe [VM_NAME] --zone=$ZONE | grep machineType
# ssh
gcloud compute instance-groups list-instances fancy-fe-mig --zone=$ZONE
gcloud compute ssh [INSTANCE_NAME] --zone=$ZONE
브로드케스팅 주소
좋은 질문이에요!
**브로드캐스트 주소(Broadcast Address)**는 네트워크에서 모든 호스트에게 메시지를 보낼 때 사용하는 특수한 IP 주소입니다.
📢 브로드캐스트 주소란?
✅ 같은 네트워크(서브넷) 내의 모든 장비에게 데이터를 보내는 데 사용하는 IP 주소
예를 들어 누군가 네트워크에 연결되었을 때, DHCP 서버를 찾기 위해 “여기 있는 모든 사람들(DHCP 서버 포함), 나 좀 도와줘!” 하는 방송을 보낼 때 이 브로드캐스트 주소를 사용해요.
🧮 어떻게 구하나요?
브로드캐스트 주소는 서브넷의 마지막 IP 주소입니다.
예: 192.168.1.0/24
- 전체 IP 범위:
192.168.1.0~192.168.1.255 - 브로드캐스트 주소:
192.168.1.255 - 네트워크 주소:
192.168.1.0 - 사용 가능한 IP:
192.168.1.1~192.168.1.254
🛠️ 실제로는 어떻게 쓰일까?
| 예시 상황 | 브로드캐스트 역할 |
|---|---|
| DHCP 요청 | 클라이언트가 IP가 없을 때 DHCP 서버에게 “누구든 IP 줄 수 있나요?” 요청 |
| ARP (주소 해석 프로토콜) | “이 IP 가진 사람 누구야?“를 전체에게 질문 |
| Wake-on-LAN | 네트워크 상의 모든 장비를 깨울 때 |
🔒 보안 및 클라우드에서는?
- 클라우드(GCP, AWS 등) 환경에서는 브로드캐스트 트래픽을 막는 경우가 많아요, 보안과 성능 때문입니다.
- 대신 멀티캐스트나 유니캐스트로 대체
🎯 요약
| 항목 | 설명 |
|---|---|
| 브로드캐스트 주소 | 네트워크 내 모든 장비에 패킷을 보내는 IP |
| 위치 | 서브넷의 가장 마지막 IP |
| 사용 예시 | DHCP, ARP, Wake-on-LAN |
| 클라우드 환경 | 대부분 제한되거나 사용 불가 |
더 알고 싶은 거 있으신가요? 예: 브로드캐스트가 멀티캐스트/유니캐스트와 어떻게 다른지 비교해볼까요? 😊
nvme 온도를 prometheus에 넣기
Prometheus와 Grafana를 함께 사용하면 시스템 메트릭(예: SSD 온도, CPU 사용률 등)을 수집하고 시각화할 수 있습니다. 아래는 Arch Linux에서 기본적인 Prometheus + Grafana 설정 및 사용법, 그리고 SSD 온도 모니터링 예시까지 포함된 가이드입니다.
🎯 목표
- Prometheus로 시스템 메트릭 수집
- Grafana로 대시보드 구성
- NVMe SSD 온도 측정 (node_exporter + custom script 활용)
🧰 1. 설치하기
✅ Prometheus
sudo pacman -S prometheus
✅ Grafana
sudo pacman -S grafana
nvme-cli
혹시 없다면 설치한다
sudo pacman -S nvme-cli
✅ node_exporter (Prometheus가 메트릭을 수집할 수 있게 해주는 에이전트)
sudo pacman -S prometheus-node-exporter
⚙️ 2. 서비스 시작 및 자동 실행 설정
sudo systemctl enable --now prometheus
sudo systemctl enable --now grafana
sudo systemctl enable --now prometheus-node-exporter
- Prometheus: http://localhost:9090
- Grafana: http://localhost:3000 (기본 로그인:
admin/admin)
📡 3. Prometheus 설정 (타겟 지정)
설정 파일: /etc/prometheus/prometheus.yml
Knative
좋아요, GCP에서의 Knative에 대해 설명드릴게요! ☁️🐳
Knative는 Kubernetes 위에서 서버리스(Serverless) 워크로드를 실행할 수 있도록 해주는 플랫폼이에요.
🚀 Knative란?
**Knative (케이네이티브)**는 Google이 주도하고 있는 오픈소스 프로젝트로,
Kubernetes 기반의 서버리스 앱 실행 플랫폼이에요.
즉,
컨테이너 기반 앱을 “필요할 때만 실행되게”, “자동 스케일링”, “이벤트 기반 실행” 등을 가능하게 해주는 K8s 확장 기능!
🧱 Knative의 구성요소 (크게 2가지)
| 구성 요소 | 설명 |
|---|---|
| Knative Serving | 앱을 서버리스로 실행. 요청 없을 때 0으로 스케일 다운도 가능 |
| Knative Eventing | 이벤트 기반으로 앱을 실행 (Pub/Sub, CloudEvents 등 트리거 지원) |
선택적으로 사용할 수 있어요. Serving만 쓰는 경우도 많아요.
Openstack vs. k8s
좋은 질문이에요!
**OpenStack과 Kubernetes(K8s)**는 둘 다 클라우드 인프라를 위한 기술이지만, 역할이 다르고 보완 관계에 있어요.
📌 요약 먼저:
🧱 OpenStack = 가상 인프라(IaaS)를 만드는 플랫폼
🚀 Kubernetes = 애플리케이션(컨테이너)를 배포·운영하는 플랫폼
→ 둘을 같이 쓰면 클라우드 인프라 + 클라우드 앱 플랫폼이 완성돼요.
🔍 개념 정리
| 항목 | OpenStack | Kubernetes |
|---|---|---|
| 목적 | 가상머신 기반 인프라 제공 (IaaS) | 컨테이너 기반 앱 오케스트레이션 (CaaS, PaaS) |
| 주요 대상 | VM, 네트워크, 스토리지 등 하드웨어 리소스 | 컨테이너(Pod), 서비스, 배포 자동화 등 |
| 운영 자원 | VM, Volume, Network | Pod, Deployment, Service |
| 주요 컴포넌트 | Nova, Neutron, Cinder 등 | kubelet, kube-apiserver 등 |
| 설치 위치 | 물리 서버 위 | VM 또는 베어메탈 위 |
🔁 어떻게 함께 쓰일까?
💡 시나리오 1:
OpenStack 위에 Kubernetes를 설치
Firebase + Firestore
좋은 질문이에요!
Firebase와 Firestore는 서로 다른 개념이지만, 밀접하게 연관된 관계예요. 간단히 말하자면:
🔥 Firestore는 Firebase 플랫폼의 데이터베이스 중 하나입니다.
🧩 관계 요약
| 개념 | 설명 |
|---|---|
| Firebase | Google이 제공하는 모바일/웹 앱 개발 플랫폼. 백엔드 기능(인증, DB, 호스팅, 푸시 알림 등)을 통합 제공. |
| Cloud Firestore | Firebase가 제공하는 NoSQL 실시간 데이터베이스 서비스. Firebase의 공식 데이터 저장소 중 하나. |
🧠 이해를 돕는 비유
- 🔧 Firebase = 앱 개발자를 위한 종합 도구 세트
- 📦 Firestore = 그 안에 들어 있는 데이터 저장용 도구 (클라우드 DB)
Firebase 안에서의 Firestore 역할
Firebase는 여러 기능을 포함해요:
Storage
[Storage 종류]
- Standard Storage: Hot data용
- Nearline Storage: Once per month. 백업이나 롱테일 멀티미디어.
- Coldline Storage: Once every 90 days.
- Archive Storage: Once a year
[Autoclass 자동클래스]
- 각 객체의 액세스 패턴에 따라 객체를 적절한 스토리 클래스로 자동전환
- 스토리지 비용 감소를 위해 액세스하지 않는 데이터를 콜드 스토리지 클래스로 향후 액세스 최적화를 위해 액세스하는 데이터를 Standard Storage로 옮깁니다.
[비용]
- 클라우드 스토리지는 최소비용이 없음 사전에 용량을 프로비저닝할 필요가 없기 때문.
[보안]
- 클라우드 스토리지는 데이터를 디스크에 쓰기전에 추가 요금 없이 언제나 서버 측에서 데이터를 암호화 함.
- 고객의 기기와 Google 사이를 이동하는 데이터는 기본적으로 HTTPS/TLS. 전송 계층 보안으로 암호화됨.
[이동]
GCP Network
🗺️ GCP에서 로드밸런서 종류 (정리)
| 이름 | 계층 | 설명 |
|---|---|---|
| HTTP(S) Load Balancer | L7 | 웹 트래픽용, 글로벌, URL 경로 기반 라우팅 |
| TCP/SSL Proxy Load Balancer | L4 | 글로벌 TCP 트래픽용, 프록시 기반 |
| Network Load Balancer (External/Internal) | L4 | 지역기반, 직접 연결 방식 (패스쓰루 방식) |
| Internal HTTP(S) Load Balancer | L7 | GCP 내부 서비스 간 통신용 |
필요하다면 로드밸런서 설정하는 방법, 혹은 **구성 예시(다이어그램)**도 만들어드릴게요. 혹시 특정 서비스 시나리오가 있으실까요? 😊
HP ENVY x360 15m-bq121dx
Woot에서 사서 방치하다 개발용 머신으로 세팅한 녀석이 하루에도 몇 번씩 죽어서 어찌 개조를 할까 고민하다 eGPU를 달아보자 조사를 하고 있다.
먼저 NVME에 PCIe를 달수 있는 것을 보고 Spec.을 찾아본다.
노트북 Spec.에서 지원하는 정도를 좀 알아본다.
HP ENVY x360 15m-bq121dx 노트북은 M.2 2280 폼 팩터의 PCIe NVMe SSD를 지원합니다. 따라서, 기존의 HDD와 함께 듀얼 스토리지 구성이 가능합니다.
권장되는 SSD 사양:
- 폼 팩터: M.2 2280
- 인터페이스: PCIe 3.0 x4, NVMe
- 용량: 최대 1TB까지 지원
주의사항:
Terraform
- IaC를 사용하면 인프라의 원하는 최종 상태만 산언하면 되고 IaC가 관리와 프로비저닝을 처리함.
[4가지 과제]
- 높은 비지니스 수요로 인해 업계 전체에 걸쳐 IT 인프라를 빠르게 확장해야 함.
- 빠른 확장에 따라 인프라를 규모에 맞게 일관되게 관리하는 등의 새로운 운영 및 기술적 병목 현상을 극복해야 함.
- 인프라가 변경되면 DevOps팀은 협업하고 변경 사항을 감사하는 데 어려움을 겪는 경우가 많음. 성공적인 배포를 위해서는 의사소통 격차를 해소하는 것이 필수적.
- 양과 규모가 증가하면서 인간의 수동적 오류도 발생.
[IaC의 장점]
- 선언적: 특정 변경을 하기 위해 정확안 단계 순서를 지정하는 대신, 인프라의 원하는 상태에 집중할 수 있음.
(예) 프로덕션 레이블을 사용하여 두 지역에 걸쳐 세 개의 서브넷을 지정할 수 있음.
Terraform은 기존 서브넷에 레이블을 추가하고 추가 지역에 두 개의 새로운 서브넷을 만들어서 원하는 상태와 일치하도록 라이블 상태를 업데이트 함.
IaC 도구는 선언적 추상화를 통해 구현 세부 정보를 관리함으로 사용자는 원하는 상태에 대한 변경 사항에 집중할 수 있음.
이러한 선언적 접근 방식을 사용하면 시스템 관리자에게 묻지 않고도 누구나 인프라 상태를 읽을 수 있음.
- Code management: 애플리케이션 소스 코드와 동일한 방식으로 관리됨.
일반적으로 Google cloud console에서 직접 변경하는 경우, 수동으로 중요한 변경사항을 식별해야 함. 이는 오류가 발생하기 쉬운 프로세스임.
IaC를 사용하면 버전과 인프라 변경 사항에 대한 전체 기록을 볼 수 있음.
인프라 전체 기록은 커밋 로그에 기록됨. 버전 제어를 통해 개발자는 변경 사항에 대해 협업할 수 있음.
(예) 방화벽을 열어야 하는 경우, 관리자가 열어줄 때까지 기다리기 보다, 간단히 풀 리퀘스트를 제출하여 포트를 열수있음.
- Auditable: 인프라의 감사 가능한 내역 기능을 제공함.
감사 로그에서 변경 사항을 확인할 수 있지만 해당 변경 사항이 적용된 이유를 이해하는 것은 어려운 경우가 많음. IaC를 사용하면 설명을 포함할 수 있음.
- Portable: 규칙을 캡슐화하고 공유 템플릿에서 지속적으로 인프라를 구축할 수 있는 재사용 가능한 모듈을 빌드 할 수 있음.
인프라를 수동으로 재구축하는 대신, 동일한 템플릿의 여러 인스턴스를 다양한 애플리케이션이나 지역에 배포할 수 있음.
Google cloud는 Cloud Foundation Toolkit에서 찾을 수 있는 재사용 가능한 모듈을 개발했음.
재사용 가능하고, 문서화되고, 테스트된 인프라 코드 라이브러리를 사용하면 인프라를 더 쉽게 확장하고 발전시킬 수 있음.
[프로비저닝 vs. 구성관리]
- 기본적으로 IaC는 클라우드 리소스의 프로비저닝과 관리에 사용되고 구성관리가 VM OS 수준 구성에 사용됨.
(예) IaC의 인프라는 VM인스턴스를 생성하고 프로비저닝하고, 구성 관리를 통해 VM의 내불르 구성함.
구성 관리란 이 색션에서 다루는 것보다 더 광범위한 주제임.
간단하게 말해서, 애플리케이션 종속성을 위해 VM을 구성하는 것과 같은 활동은 구성 관리로 간주됨.
구성은 종종 서비스 시작, 종속성 설치, 애플리케이션 설치, 업데이트 실행 등의 수동 작업으로 구성됨.
IaC는 애플리케이션 코드를 실행하는 데 필요한 인프라를 배포하기 위해 Google Cloud API를 조작하는 프레임워크를 말함.
이와 대조적으로 구성 관리란 패키지 구성과 소프트웨어 유지 관리를 말함.
프로비저닝과 구성을 구별하기 위한 사례
IaC는 Google cloud에 GKE 클러스터를 시작하는 데 관련된 작업을 자동화하고, 구성 관리 기능은 컨테이너를 GKE 클러스터에 배포하는 데 관련된 작업을 자동화 함.
코드로서 인프라를 이해하는 데 있어 중요한 원칙은 그것이 선언적이라는 것.
대부분의 프로그래밍 언어는 명령형 모델을 사용하는데, 여기서는 5개의 서버를 만드는 것과 같이 수행하고자 하는 정확한 작업을 지정할 수 있음.
이 모델은 인프라에 어려움을 줌. 스크립트를 다시 실행하면 일부가 존재하더라도 5개의 새 서버가 생성될 수 있기 때문.
필수 워크플로우로 인해 라이브 인프라와 원하는 상태 간의 차이점을 파악하기 어려워서 리소스 생성이 반복됨.
IaC를 사용하면 인프라의 원하는 상태를 선언하는 도구가 세부 정보를 결정하게 할 수 있음.
[Terraform]
리소스의 예로는 가상 머신, 컨테이너, 스토리지, 네트워크 등이 있음.
Terraform을 사용하면 인프라를 HashiCorp Configuration Language(HCL)이라는 간단하고 사람이 읽을 수 있는 언어로 코드로 표현할 수 있음.
Terraform은 구성 파일을 읽고 변경 사항에 대한 실행 계획을 제공하며, 이를 검토 적용 및 프로비저닝할 수 있음.
높은 수준에서 Terraform을 사용하면 운영자가 Google Cloud 공급자에 대한 리소스의 정의가 포함된 파일을 작성하고 해당 리소스 생성을 자동화할 수 있음.
[Terraform features]
- 다중클라우드 및 다중 API 지원
Terraform은 GitHub, Kubernetes와 같은 API 노출 서비스와 Google Cloud 외에도 모든 주요 클라우드 공급자를 지원함.
- 엔터프라이즈 지원을 포함하여 셀프 호스팅부터 완전 관리형까지 세 가지 에디션이 제공됨.
- Google Cloud 배포를 위한 공개적으로 사용이 가능한 모듈이 있는 레지스트리를 포함한 대규모 커뮤니티
- 구성보다는 인프라 프로비저닝이 중요.
Google Cloud용 Terraform을 사용하면 리소스를 프로비저닝할 수 있음. 즉, 리소스 블록을 사용하여 VM, 네트워크, 방화벽과 같은 인프라 요소를 정의할 수 있음.
리소스간의 명시적 종송성을 만들면 특정 리소스는 다른 리소스가 생성된 후에만 생성될 수 있음. 재사용 가능한 모듈을 만들면 주어진 리소스를 생성하는 방법을 표준화할 수 있음.
검증 규칙을 사용하여 주어진 리소스 인수에 대해 제공되는 값을 제한할 수 있음.
[IaC configuration workflow]
- Scope: Confirm the resources required for a project
- Author: Author the configuration files based on the scope
- Initialize: Download the provider plugins and initialize directory
- Plan: View execution plan for resources created, modified, or destroyed
- Apply: Create actual infrastructure resources
[Terraform use case]
- Manage infrastructure: 변경 불가능한 접근 방식이 사용. 즉, 서비스와 인프라를 업그레이드하거나 수정하는 데 관련된 복잡성을 줄이는 코드를 작성
- Track changes: 새로운 변경 사항이 계획되거나 적용될 때마다 Terraform이 인프랄 상태를 수정하기 전에 변경 사항을 승인하는 메시지가 표시됨.
Terraform을 사용하여 인프라를 생성하면 상태 파일이 자동으로 생성됨. 상태파일은 인프라의 현재 상태를 반영하고 구성에서 수정된 Google Cloud 리소스의 양과 유형을 제공.
- Automate changes: 변경사항을 자동화하는데 사용. 구성파일은 본질적으로 선언적이므로 인프라를 구축하기 위해 자세한 지침을 작성할 필요가 없음. 당신은 단지 최종 상태만 정의.
Terraform은 종속성을 관리하고 리소스를 프로비저닝함.
- Standardize the configuration: 구성을 표준화하는데에도 사용됨.
모듈을 사용하면 시간을 절약하고 모범 사례를 구현할 수 있음. Terrform Registry에서 공개적으로 사용 가능한 모듈을 활용할 수 있음.
Terraform을 사용하면 팀에서 프로비저닝하고 사용할 수 있는 리소스 유형에 대한 정책적용을 자동화할 수도 있음.
[Using terraform]
- 구성 파일에 인프라를 코드로 작성해야 함.
구성 파일은 Terraform에 프로비저닝하려는 리소스를 설명함.
- Terraform은 원하는 상태에 대한 실행 계획을 생성한 다움,
- 해당 계획을 실행하여 설명된 인프라를 구축
- 구성이 변경되면 Terraform은 변경된 내용을 확인하고 적용할 수 있는 증분 실행 계획을 만들 수 있음.
[에디션]
- Commuity Edition: 로컬 머신이나 클라우드의 컴퓨팅 리소스에 다운로드할 수 있는 뮤료 소프트웨어 버전
버전관리 기능이 없음. CLI만 제공
- Cloud Edition. GUI. 협업 환경에 유용. [무료, 표준, 플러스] 플랜. 동시배포. 운영 오버헤드가 낮음.
- Enterprize Edition:GUI. 동시배포. 온프레미스 또는 귀하가 제어하는 인프라에 호스팅. 운영 오버헤드가 높음.
[HCL syntax]
- Blocks: 블럭은 간단할 수도 있고, 다른 블럭을 포함하도록 중첩될 수도 있음. [<block type> "<block lable>" "<block lable>"]
- Arguments: 블럭의 일부이며 이름에 값을 할당하는 데 사용. 일부 블록에는 필수 인수가 있고, 다른 블록에는 선택 인수가 있음.
- Identifiers: 인수, 블록 유형 또는 Terraform 특정 구성 요소의 이름. 식별자에는 문자, 밑줄, 하이픈, 숫자가 포함될 수 있지만 숫자로 시작할 수는 없음.
- Expressions: 표현식은 코드 블록 내의 식별자에 값을 할당하는 데 사용될 수 있음. 간단할수도 있고 복잡할수도 있음.
- Comments: #로 시작. single line.
[Concepts]
- 리소스는 인프라 구성요소를 정의하는 코드블럭.
리소스는 키워드 resource로 식별. 그 뒤에 리소스의 유형과 사용자 지정 이름이 붙음.
리소스 유형은 구성에 정의된 공급자에 따라 달라짐.
Terraform은 리소스 유형과 리소스 이름을 사용하여 인프라 요소를 식별함.
- providers.tf에는 공급자 관련 정보
Terraform은 공급자가 선언되면 루트 구성에서 공급자 플러그인을 다운로드함.
공급자는 특정 API를 Terraform 리소스로 노출하고 상호 작용을 관리함.
공급자 구성은 Terraform 구성의 루트 모듈에 속함.
- variables.tf
입력변수는 Terraform의 매개변수 역할을 하므로 소스 코드를 변경하지 않고도 쉽게 사용자 정의하고 공유할 수 있음.
변수가 정의되면 런타임에 해당 값을 설정하는 다양한 방법이 있음. 여기에는 변수, CLI옵션, 키 또는 값 파일 등이 있음.
리소스 속성은 런타임에 정의하거나 확장자가 .tvars인 파일에서 중앙에서 정의할 수 있음.
배포 계획에서 속성을 쉽게 분리할 수도 있음.
- terraform.tvars
변수 입력값. 이 파일이나 CLI등에서 설정.
- outputs.tf
리소스의 출력값을 보관.
Terraform이 관리하는 각 인스턴스는 구성의 다른 곳에서 사용할 수 있는 값을 갖는 속성을 내보냄.
필요한 경우 풀력 값은 해당 정보 중 일부를 노출하는 방법임.
일부 리소스 속성은 생성 시 계산됨.
(예) 버킷 생성 시 리소스의 셀프 링크나 버킷의 URL이 생성됨. 이러한 계산된 속성은 버킷에 액세스하거나 객체를 업로드하는 데 필요할 수 있음.
출력값을 사용하면 이 정보를 출력하고 접근 가능하게 만들 수 있음.
출력키워드(Outputs:) 뒤의 레이블은 이름이며, 유효한 식별자아여 함.
루트 모듈에서는 이 이름이 뷰어에 표시됨.
자식 모듈에서는 값에 접근하는 데 사용할 수 있음.
값의 인수는 사용자에게 결과를 반환하는 표현식을 받음.
- terraform.tfstate
리소스의 상태를 상태파일에 저장.
기본적으로 상태 파일은 로컬에 저장되지만 원격에도 저장할 수 있음. 팀 환경에서 작업할 때는 원격저장이 종종 선호되는 방식임.
자동으로 생성되고 갱신됨으로 수정하면 안됨.
- Modules
단일 디렉토리에 있는 Terraform 구성 파일의 집합.
하나 이상의 .tf 파일이 들어 있는 단일 디렉토리로 구성된 간단한 구성조차도 모듈로 간주됨.
모듈은 Terraform에서 코드를 재사용하는 기본 방법. 코드를 검색할 수 있는 소스를 지정하여 재사용함.
소스는 로렄이거나 원격일 수 있음.
HashiCorp 모듈 레지스트리에서 업스트림 모듈을 사용할 수도 있고, 직접 만들 수도 있음.
[command]
- terraform init: 공급자 초기화
- terraform plan: 리소스 미리보기.
- terraform apply: 리소스 생성
- terraform destroy: 리소스 파괴
- terraform fmt: 표준 규칙에 맞게 자동으로 포맷(형식)을 지정. 마치 Prettier나 Black 같은 포맷터 도구라고 생각하면 됩니다!
[IaC for Google Cloud]
- Introduction to resources
- Meta-arguments for resources
- Resource dependencies
- Variables
- Variables best practices
- Output values
- Terraform Registry and Cloud Foundation Toolkit
[Meta-arguments]
- count: 정의한 값에 따라 여러 인스턴스를 생성
- for_each: 맵이나 문자열 집합에 따라 여러 인스턴스를 생성
- depends_on: 명시적 종속성을 지정하는데 사용
- lifecycle: 리소스의 생명주기를 정의. 규정준수 목적으로 리소스 파괴를 방지하고 교체된 리소스를 파괴하기 전에 리소스를 만들수 있음. 가용성을 위해 자주사용됨.
- provider: 기본이 아닌 공급자 구성을 선택함. 공급자에 대해 기본값을 포함하여 여러 구성을 가질수 있음.
[count]
- 중복으로 선언하지 말고 수식으로 사용 할 수 있음. 0부터 시작. 보간법을 사용해서 문자열에 count 인덱스 변수를 포함함.
count = 3
name = "dev_VM${count.index +1}"
> "보간법"은 두 점 사이의 값을 추정하거나 중간 값을 계산할 때 사용하는 수학적 기법이에요. 데이터를 부드럽게 연결하거나 누락된 값을 채우는 데 자주 사용돼요. 영어로는 interpolation이라고 해요.
- 일부 인수에 정수에서 직접 파생될 수 없는 고유한 값이 필요한 경우 for_each를 사용하는 것이 더 안전.
for_each인수는 값의 문자열이나 맵에 할당될 수 있음.
for_each = toset(["web1", "web2", "web3"])
tags = {
Name = each.key
}
[Dependency graph]
- 인프라를 구축하는 동안 인프라가 어떻게 연결되고 상호 의존적인지 시각적으로 표현.
- 종속성 그래프는 배포하기 전에 인프라를 이해하는 데 도움이 됨.
- 속성은 런타임 동안 보간되고, 변수, 출력, 값, 공급자와 같은 기본요소는 종속성 트리에서 연결됨.
- Terraform은 올바른 작업 순서를 결정하기 위해 종속성 그래프를 만듬
- 여러 리소스가 있는 더 복잡한 사례에서 Terraform은 안전하다고 판단될 때 병렬로 작업을 수행함.
- Implicit dependency 암시적 의존성. 알려져 있음.
- Explicit dependency 명시적 의존성. 알려져 있지 않음.
하나의 리소스 생성이 다른 리소스에서 생성된 정보에 따라 달라짐.
(예) 네트워크가 생성되지 않으면 컴퓨팅 인스턴스를 생성할 수 없음. 마찬가지로, 정적 IP가 예액될 때까지 Compue Engine 인스턴스에 정적 IP주소를 할달할 수 없음. 이러한 종속성은 암묵적임.
리소스가 다른 리소스가 생성된 뒤에야 생성되어야 한다면, Terraform에서 볼 수 없는 종속성을 명시적으로 언급해야 함.
(예) 특정 Cloud Storage 버킷을 사용하여 애플리케이션을 실행하는 경우, 해당 종속성은 애플리케이션 코드 내부에서 구성되므로 Terraform에서는 볼 수 없음. depend_on을 사용하여 명시적으로 선언.
depends_on = [<resource_type>.<resource_name>]
[Variables]
- 변수를 사용하면 리소스 간에 공유되는 값을 매개변수화할 수 있음.
입력 변수는 Terraform의 매개변수 역할을 하므로 소스 코드를 변경하지 않고도 쉽게 사용자 정의하고 공유할 수 있음.
변수가 정의되면 런타임에 해당 값을 설정하는 다양한 방법이 있음. 여기에는 변수, CLI옵션, 키 또는 값 파일 등이 있음.
- 변수는 변수 블럭에 선언해야 함. variable.tf
variable "<variable_name>" {
type = <variable_tpye>
description = "" #문서화에 사용됨으로 관리자보다는 사용자 관점에서 작성되어야.
default = ""
sensitive = true/false # 명력 출력이나 로그 파일에 민감정보가 표시되지 않도록 보호하는 목적.
}
- 변수에 대한 필수 인수가 없음으로 변수 블록은 비어 있을 수 있음.
- 변수 타입: Bool, Number, String
- 변수의 사용은 var.<변수이름>
- 기본값은 환경값이나 .tfvars파일 또는 -var 옵션에 값을 할당하여 재정의 할 수 있음.
[변수적용]
- .tfvars
tf apply -var-file my-vars.tfvars
- CLI # 가장 높은 순위
tf apply -var project_id="project_id"
- environment variables
$TF_VAR_project_id="project_id" \
tf apply
- terraform.tfvars / terraform.tfvars.json, .auto.tfvars, auto.tfvars.json
tf apply
- validation 블럭이 있음
variable "test" {
type = string
validation {
condition = conditions(["A", "B", "C"], var.storageclass)
error_message = "Allow storage class are.."
}
}
[values 베스트 프랙티스]
- 각 인스턴스나 환경에 따라 달라지는 값만 매개변수화 함.
변수를 노출할지 여부를 결정할 때, 해당 변수를 변경하기 위한 구체적인 사용 사례가 있는지 확인.
변수가 필요할 가능성이 작다면 공개하지 말아야.
기본값을 사용하여 변수를 변경하거나 추가하는 것은 이전 버전과의 호환성이 있지만, 변수를 제거하는 것은 그렇지 못함.
루트 모듈의 경우 .tfvars 변수 파일을 사용하여 변수에 값을 제공함. var파일과 명령줄 옵션을 번갈아 사용하지 말것.
명령줄 옵션은 일시적이고 잊기 쉬우며, 소스제어에 체크인 할 수 없음.
- 변수에 용도나 목적에 맞는 설명적 이름을 지정. 디스크 크기나 RAM크기와 같은 숫자 값을 나타내는 변수는 단위를 사용하여 이름을 지정해야 함.
Google Cloud API에는 표준 단위가 없음으로 이 명명규칙을 따르면 구성 유지 관리자가 에상하는 입력 단위가 명확해짐.
조건 논리를 단순화하려면 Bool변수에 긍정적 이름을 지정
(예) enable_external_access
- 변수에는 설명이 있어야 함.
[Output values]
- 출력값은 일반 프로그램 언어의 반환값과 유사. 출력을 사용하면 명령줄에서 생성한 인프라 리소스에 대한 정보를 볼 수 있음.
- 가장 일반적인 사용은 배포 후 CLI에서 루트 모듈 리소스 속성을 인쇄하는 것.
대부분의 서버 세부 정보는 배포 시에 걔산되며, 생성 이후에만 추론할 수 있음.
- 출력 값은 한 리소스에서 생성된 정보를 다른 리소스로 전달하는 데에도 사용됨.
(예) IP주소와 같은 서버별 값을 아 정보가 필요한 다른 리소스로 추론할 수 있음.
- 출력값은 출력 블럭을 사용하여 선언됨.
output "name" {
description = "Note"
value = <resource_type>.<resource_name>.<attribute>
sensitive = true/false
}
- 어디에나 선언 될 수있지만, 권장되는 곳은 output.tf라는 별도 파일에 선언하는 것임.
[outputs 베스트 프랙티스]
- 계산된 정보와 같은 유용한 정보만 출력
- 단순히 변수를 반복하거나 알려진 정보를 제공하는 값은 출력하지 말것.
(예) 네트워크 리소스 id는 리소스의 식별자이고, Gateway_ip4는 네트워크에서 기반 라우팅을 위한 게이트웨이 주소. self_link는 생성된 리소스의 URI.
- 변수와 마찬가지로 의미 있는 이름과 설명을 제공할 것.
- 모든 출력값을 output.tf라는 파일에 포함하도록 코드를 구성.
- 민감한 출력을 표시. 민감한 상태를 수동으로 관리하는 대신. 민감한 상태 관리에 대한 기본 제공 지원을 활용.
[The Registry]
- 대화형 모듈
- 모든 인프라 API를 관리하는 플러그인, 일반적인 인프라 구성 요소를 빠르게 구성하는 사전 제작된 모듈, 고품질 Terraform 코드를 작성하는 방법에 대한 예시 제공.
- CFT Cloud Foundation Toolkit 사용가능. CFT는 Google Cloud 모범 사례를 반영하는 Terraform용 일련의 참조 모듈을 제공. Terraform 블루프린트라고 부름.
- Terraform모듈과 End-To-End 모듈 예제를 모아 단일 단위로 복제하고 빠른 프로토타입을 만들거나 조직에서 사용할 수 있도록 분해 및 수정한 CFF Cloud Foundation Fabirc도 있음.
- CFT는 구글 직원이 관리함.
- CFT를 사용하면, 각 프로젝트의 역할을 개별적으로 업데이트하는 대신, 동일한 모듈 내에서 여러 프로젝트의 IAM 역할을 유지 관리할 수 있음.
[Infrastructure Manager]
- 인프라스트럭처 관리자 또는 인프라 관리자는 Google Cloud 인프라 리소스의 배포와 관리를 자동화하는 관리형 서비스.
- Infra Manager는 리소스에 대한 애플리케이션 배포를 관리하지 않음.
- 애플리케이션 배포를 관리하려면 Cloud Build 및 Cloud Deploy와 같은 Google Cloud제품을 사용할 수 있음.
혹은 타사 도구나 툴 체인을 사용할 수 있음.
[Module]
(예) 사용자 지정 네트워크에서 웹 서버를 만들어야 함.
[Terraform state]
- 인프라 구성의 메타데이터 저장소
- Terraform은 관리하는 리소스의 상태를 상태 파일에 저장함.
- 기본적으로 상태는 terraform.tfstate라는 파일에 저장되지만, 팀 환경에 권장되는 원격으로 저장가능함.
- Terraform은 로컬 상태를 사용하여 계획을 만들고 인프라를 변경함.
어떤 작업도 수행하기 전에 Terraform은 실제 인프라로 상태를 업데이트하기 위해 새로 고침을 수행함.
Terraform state의 주요 목적은 원격 시스템의 객체와 구성에서 선언된 리소스 인스턴스간의 바인딩을 저장하는 것임.
Terraform이 구성 변경에 대응해 원격 객체를 생성하면 특정 리소스 인스턴스에 대해 해당 원격 객체의 ID를 기록함.
그러면 Terraform은 향후 구성 변경에 대응하여 해당 객체를 업데이트하거나 삭제할 가능성이 있음.
리소스 블록 내에서 생성된 모든 인프라 구성 요소는 Terraform 상태 내에서 해당 이름으로 식별됨.
처음으로 Terraform 구성을 적용하면 인프라 리소스가 생성되고 리소스 블럭에 언급된 이름에 대한 참조가 포함된 상태 파일이 자동으로 생성됨.
리소스에 이미 Terraform 상태 파일 내에 항목이 있는 경우 Terraform은 구성을 상태 파일과 현재 라이브 상태와 비교하고 비교를 바탕으로 계획이 생성됨.
계획이 적용되면 정의된 구성에 맞게 리소스가 업데이트됨.
구성이 적용되면 Terraform 상태 파일이 업데이트되어 인프라의 현재 상태로 반영됨.
원격 API 제한으로인해 인수를 제자리에서 업데이트할 수 없는 경우 리소스가 파괴되고 다시 생성됨.(엥?)
현재 구성에서 리소스가 제거되었지만 상태 파일에 항목이 있는 경우 Terraform은 구성을 비교하여 더 이상 존재하지 않는 리소스를 삭제함.
[Store state files]
- 여러 개발자가 동시에 Terraform을 실행하고 각 머신이 현재 인프라에 대한 자체적인 이해를 가지고 있는 경우 기본 구성은 까다로워질 수 있음.
- 팀인 경우 상태파일을 중앙에 원격으로 저장해야함.
[Issue with storing the Terraform state locally]
- No shared access: 공유되는 위치에 저장해야함
- No locking: 파일을 잠글수 없음. 동시에 Terraform을 실행하면, 여러 Terraform 프로세스가 상태 파일을 업데이트하기 때문에 RACE(Race 경쟁) 조건이 발생할 수 있음.
아러한 조건은 충돌, 데이터 손실, 상태 파일 손상으로 이어질 수 있음.
- No confidentiality: 기밀이 제공되지 않음.
[Benefits of storing state file in a remote location]
- Automatic update
원격 백엔드를 구성하면 Terraform은 계획을 실행하거나 명령을 적용할 때마다 백엔드에서 상태를 자동으로 로드함.
또한 각 적용 후 백엔드에 상태 파일을 자동으로 저장하므로 수동 오류가 발생할 가능성이 없음.
- Locking
원격 클라우드 스토리지 버킷은 기본적으로 상태 잠금을 지원함.
여러 개발자가 동시에 Terraform을 실행하더라도 동시 업데이트로 인해 파일이 손상되지 않도록 파일을 잠글 수 있음.
- Secure access
원격 파일 저장은 로컬 저장보다 더 안전함.
클라우드 스토리지 버킷은 기본적으로 전송 중 암호화와 디스크 암호화를 지원함.
Cloud storage에는 액세스 권한을 구성하는 여러 가지 방법이 포함되어 있어 상태 파일에 누가 액세스할 수 있는지 제어할 수 있음.
(예) 버킷에 IAM 정책을 사용할 수 있음.
Cloud Storage 버킷은 저장 시 암호화되지만, 고객이 제공한 암호화 키를 사용하면 보안을 더 강화할 수 있음. GOOGLE_ENCRYPTION_KEY환경변수를 사용하면 보호계층을 추가로 제공할 수 있음.
비밀은 처음부터 상태 파일에 있어서는 안 되지만, 방어를 위한 추가 조치로 항상 상태를 암호화해야함.
- main.tf에 Google Cloud 버킷 리소스 선언
backend.tf 선언. 리소스 타입이 backend임
terraform {
backend "gcs" {
bucket = "..."
prefix = "terraform/state"
}
}
Terraform은 명령을 실행하기 전에 이 버킷에서 최신 상태를 가져오고, 명령을 실행한 후에는 최신 상태를 버킷에 푸시함.
[Terraform state best practices]
- 팀 환경에서 원격 상태를 사용하면 상태 파일을 잠그고 버전관리할 수 있음.
버전 제어에서 중요한 정보를 분리하고, 빌드 시스템과 권한이 높은 관리자만 원격 상태 버킷에 액세스할 수 있도록 해야함.
실수로 개발 상태를 소스 제어에 커밋하는 것을 방지하려면 Terraform 상태 파일에 .gitignore를 사용해야함.
- 비밀을 상태에 저장하면 안됨.
- 상태파일을 암호화해야함.
- 상태를 수동으로 수정하지 말아야 함.
CI/CD on google cloud
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
export REGION=us-east1
gcloud config set compute/region $REGION
gcloud services enable \
cloudresourcemanager.googleapis.com \
container.googleapis.com \
artifactregistry.googleapis.com \
containerregistry.googleapis.com \
containerscanning.googleapis.com
git clone https://github.com/GoogleCloudPlatform/cloud-code-samples/
cd ~/cloud-code-samples
gcloud container clusters create container-dev-cluster --zone=us-east1-d
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-east1-d/container-dev-cluster?project=qwiklabs-gcp-00-001b477f5ece
kubeconfig entry generated for container-dev-cluster.
NAME: container-dev-cluster
LOCATION: us-east1-d
MASTER_VERSION: 1.31.6-gke.1020000
MASTER_IP: 34.148.68.137
MACHINE_TYPE: e2-medium
NODE_VERSION: 1.31.6-gke.1020000
NUM_NODES: 3
STATUS: RUNNING
gcloud artifacts repositories create container-dev-repo --repository-format=docker \
--location=$REGION \
--description="Docker repository for Container Dev Workshop"
gcloud auth configure-docker us-east1-docker.pkg.dev
cd ~/cloud-code-samples/java/java-hello-world
docker build -t us-east1-docker.pkg.dev/qwiklabs-gcp-00-001b477f5ece/container-dev-repo/java-hello-world:tag1 .
docker push us-east1-docker.pkg.dev/qwiklabs-gcp-00-001b477f5ece/container-dev-repo/java-hello-world:tag1
cd ~/cloud-code-samples/
cloudshell workspace .
리눅스에서의 바이너리 배포 문제
리눅스에서의 바이너리 배포 문제
리눅스에서는 실행 파일을 배포하는 주요 방법이 무려 네 가지나 존재하며 각각 문제를 안고 있음 생 바이너리: 대부분의 환경에서 동작하지 않음
- AppImage: 모든 의존성을 포함하지만, 완벽한 보존성은 미지수
- Flatpak: 앱마다 샌드박스를 제공함
- Snap: 또 다른 샌드박스 기반 패키지 관리자 이들 모두 설치, 업데이트, 삭제 방식이 서로 다르고 동시에 공존 가능함 장기적인 앱 보존 및 재실행에는 대부분 적합하지 않으며, 20년 후 실행 가능성은 거의 없음
힘들기는 하지만. 취미생활하는 입장에서는 퀴즈의 다양성이 줄어드는 현상이 발생하는데?
rocky linux + SELinux + 502 Bad Gateway
Rocky linux에서 갑자기 무슨 생각인지 dnf update를 날리고 나서 몇일 있다가 보니.. 서비스가 전부 죽어있다.
GPT에 대충 던저보니. iptable 어쩌구 저쩌구 하는 메시지를 알려준다.
따라하다가 생각해보니. 이건 아니다 싶어. 다시 iptable을 죽이고 생각한다.
SELinux인거다.
# SELinux 로그에서 관련 오류가 있는지 확인:
sudo ausearch -m AVC,USER_AVC -ts recent
# 만약 SELinux가 문제라면 아래 명령어로 허용 설정을 할 수 있습니다.
sudo setsebool -P httpd_can_network_connect 1
# 위 설정 후 Nginx를 재시작하세요.
sudo systemctl restart nginx
다시 살리기는 했지만 말이다.
HP Envy + Freezing
리퍼로 몇 년 전인가 사서 방치하다가 개발용 머신으로 세팅해서 사용하는 녀석이 가끔 화면이 Freezing되는데, 마우스 커서는 움직이는데, 그 아래있는 화면이 응답이 없는 현상에 대해서 원인이 무엇일까 몇 달을 착고있다.
GPT에게 물어봐도 다 해본 방법밖에 없는 것을 보니. 이건 다른 문제인가 싶기도 하고.
Arch Linux에서 AMD 그래픽 카드가 멈추는(freezing) 문제를 점검하고 해결하는 방법을 정리해 보겠습니다.
🔍 1. 시스템 로그 확인 (freeze 원인 분석)
Freeze의 원인을 파악하려면 로그 확인이 필수입니다.
1.1 dmesg 로그 확인
sudo dmesg -l err,crit,alert
- 시스템 부팅 후 발생한 오류(error), 치명적(critical), 경고(alert) 메시지를 출력합니다.
amdgpu관련 오류가 있는지 확인하세요.
sudo dmesg | grep -i amdgpu
amdgpu드라이버에서 발생한 오류만 필터링할 수 있습니다.
1.2 journalctl 로그 확인
sudo journalctl -p 3 -xb
- 현재 부팅(
-b)에서 발생한 심각한(-p 3) 오류만 출력합니다. amdgpu관련 메시지가 있는지 확인하세요.
sudo journalctl -k | grep amdgpu
- 커널 로그에서
amdgpu관련 메시지만 필터링할 수 있습니다.
⚙ 2. AMD 드라이버 상태 점검
2.1 lsmod로 AMD 드라이버 확인
lsmod | grep amdgpu
amdgpu모듈이 로드되어 있어야 합니다.- 아무것도 나오지 않는다면 드라이버가 제대로 로드되지 않은 것입니다.
2.2 lspci로 GPU 확인
lspci -k | grep -A3 "VGA"
- AMD GPU가 감지되었는지 확인하세요.
- 출력 결과에서
Kernel driver in use: amdgpu가 보이면 정상적으로 로드된 것입니다.
2.3 glxinfo로 OpenGL 드라이버 확인
glxinfo | grep "OpenGL renderer string"
- AMD GPU가 제대로 사용되고 있는지 확인하세요.
- 이 명령어가 실행되지 않으면
mesa-utils를 설치하세요:sudo pacman -S mesa-utils
🔄 3. 커널 및 드라이버 문제 해결
3.1 최신 Linux 커널 또는 LTS 커널로 변경
최신 커널 사용 중인데 문제가 발생하면 LTS 커널로 변경해보세요.
tensorflow + python 3.13 + 3.12 + 3.11 +3.10
Google ML Sample을 풀어보려고 jupyter notebook에 Tensor를 설치하려고 하고 있었다.
- System에 설치된 Python 버전은 3.13
- tensorflow는 설치가 되었는데, tensorflow_hub를 살펴보니 3.12만 있다.
- 거기다가 tensorflow_text는 3.10만 있다.
- uv를 살펴보다 보니, python version을 지정해서 설치 할 수 있다.
- .python-version 파일의 버전을 수정 한 상태로 venv를 생성하면, 알아서 잘 만들어 준다.
uv python list
uv python install ***특정버전
- jupyter를 3.10에서 실행하는 방법에 대해 잠시 고민했는데, 그냥 venv환경에 jupyter를 add하고 실행하면 자연스럽다
훌륭하다.
tooljet + appsmith
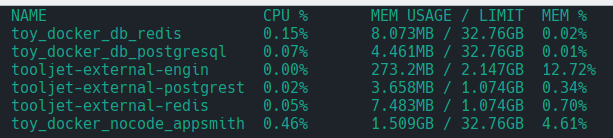 |
|---|
| tooljet과 appsmith의 메모리 사용량 |
streamlit으로 만들고있는 private quee의 관리자 페이지를 만들다가.. 이건 아닌거 같아 한눈 판 것이 NoCode Tool로 튀었다.
먼저 retool에서 화면을 하나 만들어 보고, 느리고 안정성이 부족해서 그 self-host로 찾아보다 tooljet을 가지고 열심히 세팅을 하다가, @react-oauth/google를 설치하는 부분에서 좌절하고, appsmith를 설치 해 보는데, 이 녀석 대단하다.
- 설치가 단순하다. (tooljet은 tooljet db를 exclude하는 기능을 제공하기 때문에, 우수하지만 오히려 복잡 해 질 여지를 준다.)
- 화면 정리 정돈이 잘 되어있다
- 구현은 안해봤기에 얼마나 안정적인지는 모르겠다.
그런데 저 메모리 사용량은 좀 곤란하다.
Podman + host.containers.internal
MPD Client에서 실제 음악 재생용으로 올려둔 MPD container를 연결 할 수 없는 현상이 벌어진다.
이게 원래 Docker에서 잘되던 것이고, (기억으로는) Podman에 올렸을 때도 잘되었던거 같은데 말이다.
이리저리 gpt에 질문을 해 봐야 별로 소득이 없다.
결국 “10.89.2.1"이라는 (잘 알려진) host ip로 바꾸고 만다.
SELinux + systemctl
Feb 21 16:05:56 change53 systemd[1077931]: toy_redis_to_postgres.service: Failed to locate executable /usr/local/toy_redis_to_posgres/toy_redis_to_postgres: Permission denied
Feb 21 16:05:56 change53 systemd[1077931]: toy_redis_to_postgres.service: Failed at step EXEC spawning /usr/local/toy_redis_to_posgres/toy_redis_to_postgres: Permission denied
Ubuntu에 잘 배포했던 녀석을 Rocky에 다시 배포 할 일이 있어서 서비스를 등록하고 start를 시키는데 permission error가 난다.
무언가 가물가물 기억은 잘 안 나는데, 응용프로그램을 등록 해 줬었던거 같다.
한참을 해메다 보니 gpt가 대충 알려줘서 해결한다.
# 상태체크
sudo ausearch -m AVC,USER_AVC -ts recent
# 일시적으로 강제 비활성화
sudo setenforce 0
sudo systemctl restart myapp
# SELinux 쩡책 수정
sudo chcon -t bin_t /usr/local/bin/myapp
서비스가 정상 작동하는 것을 보고 SELinux관련 임시 설정을 복원하는등 작업을 했더니..
GLIBC_2.34 not found
xx@yy:/usr/local/toy_redis_to_posgres$ ./toy_redis_to_postgres
./toy_redis_to_postgres: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.34' not found (required by ./toy_redis_to_postgres)
./toy_redis_to_postgres: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.32' not found (required by ./toy_redis_to_postgres)
Redis data를 Postgres로 복제하는 프로그램을 하나 만들어 설치를 하는데, glibc관련 오류를 보인다.
막연하게 goLang을 컴파일되는 python이라고 생각했더니, 그건 또 아닌거 같다.
glibc를 설치하려다 생각 해 보니. 그냥 goLang을 설치하고 build하는 것이 더 자연스러워 보인다.
goLang 1.23 > 1.22 > 1.24
goLang에서 posgres에 insert 할 일이 있어서 ORM을 알아보다 google의 ent를 사용 해 보기로 한다.
홈페이지 엤는 내용을 따라 하다보니, 영 이상한 오류를 보이며 안되서 구글링을 하다보니 1.22까지만 지원한다는 것을 보고 버전을 내려봐도 영 해결 될 가능성이 안보이다.
거기다… 다른 환경이 꼬이는지 1.23으로 upgrade해야 한다는 메시지를 VSCode등 여기저기서 나온다.
goLang에 가보니 최신 버전은 1.24이다.
동일한 방식으로 update하고 다시 ent를 따라 해 보는데. 정상적으로 잘된다.
결국 파이썬에서 겪었던 버전간의 여러 문제들은 goLang에도 여전히 존재한다는 느낌이다.
prql은 어떤 사람들에게 적합할까?
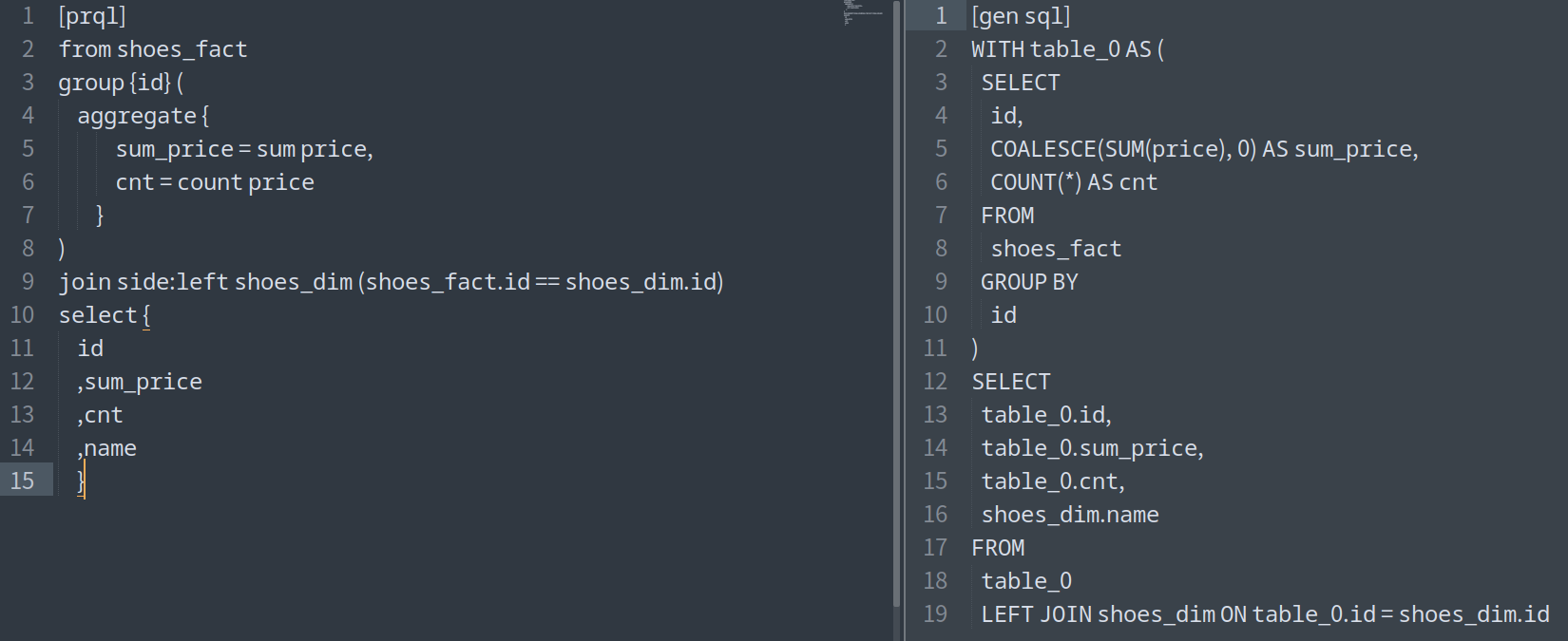 |
|---|
| 간단한 prql과 생성된 sql |
prql을 살펴보고 있다.
사실 이 녀석은 나름 합리적이라고 주장하는 문법으로 좋은 결과를 제공 할 것으로 예상되는 SQL을 생성하는 것이 그 주요 기능이다.
대한민국의 금융권 SI하는 많은 개발자들은 아주 긴 query를 짤 수 있다는 것에 대단한 자부심을 가지고 있는 경우도 있는데 말이다.
생성된 SQL을 보면. 튜너가 과연 튜닝을 해 주고 싶을까 싶은 생각이 드는 것은.
흔히 금융권 차세대에 이 녀석으로 어떻게 적용 해 볼 생각은 안해도 되겠다 싶다.
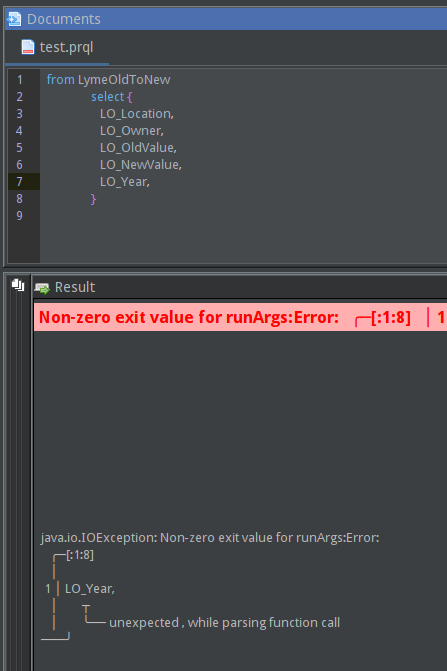
prql + QStudio + Ctrl+Enter
 |
|---|
| Ctrl+Enter는 오류가 발생한다. |
pqrl을 테스트 해 보기 위해서 QStudio를 설치하고 따라 해 보고 있었다.
- 처음 duckdb 파일을 여는 와중에 접속 port가 보여서 duckdb가 server mode로 접속해야 하나 싶었으나. (잘못된 생각이었다.)
- Query를 기록한 파일의 확장자가 prql이어야 동작(인지)하는 것은 쉽게 따라 갔으나. 아무리 실행(하던 버릇데로 Ctrl+Enter)해 봐야 위와 같은 오류만 나온다.
- 그런데 단순 from table-name 하는 것은 잘 나온다.
- 알고봤더니 Ctrl+E 혹은 실행 아이콘으로 해야 정상적으로 파싱하고 인지한다.
- 그렇다면 Ctrl+Enter는 어떤 기능일까?
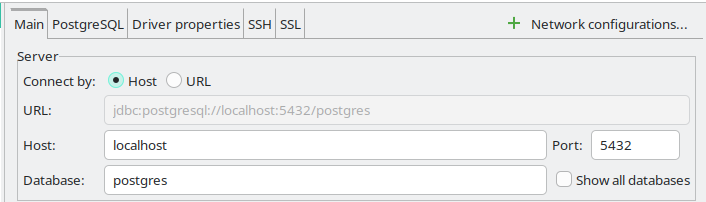
DBeaver + SSH Tunneling
 |
|---|
| SSH로 연결 할 때 IP는 local host이다. |
Oracle Cloud에서 메모리 부족 사태를 겪은 후 DEMO용 DBMS에 대해서 가급적이면 sqlite를 사용하려고 노력하고 있었다.
그런데, wiki.js라던지 FastAPI 공식 Template을 사용 해 보면서, 결국 DB는 postgresql로 넘어갔구나 하는 생각을 하고, 메모리를 얼마나 점유하는지 확인 해 보니, 그리 걱정 할 수준은 아니라고 판단해서 올려 놓기로 한다.
막상 container를 올려놓고 보니, 관리하는 것이 영 불편할것 같아, remote db에는 직접 접속하지 않겠다는 기존 생각을 고쳐먹고, ssh tunneling을 시도 해 보는데.
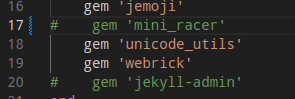
jekyll + podman = 매번 할 때마다 느끼는 것이지만.
 |
|---|
| 이번에 주석 처리 한 것 |
매번 시스템을 바꾸거나하면서 jekyll을 재설치해야 하는 경우. 거의 몇 달이거나 1년만에 하는 경우가 많다보니 잊는다.
이번에 노트북을 새로 밀면서 거의 1년만에 다시 올리려고 보니 이미지를 빌드하는 과정에서 오류를 내 뱉는다.
무얼까? podman으로 바꿔서 안 되는 것일까?
jekyll이미지를 다시찾아보다가 마땅찬으니 build script를 다시 읽어보고, 별 거 없으니, Gemfile을 유심히 본다.
음… 오류메시지를 다시 본다.
mini_racer
얼마간의 시간이 지났으니 이번에는 저 녀석이 나가떨어졌나보다. 하면서 주석처리하고 다시 빌드하니 먹는다.
PCI passthrough
HASS를 올려 놓은 proxmox에서 블루투스장치가 필요해서 알아보니 PCI passthrough가 필요한 모양이다만.
과연 내가 사용하고 있는 자치에서 이게 된다는 건지 안된다는 건지 조사가 필요하다.
-
Blacklist Driver
Proxmox VE에서 PCI 패스스루를 설정할 때, 특정 장치에 대해 기본적으로 로드되는 커널 드라이버를 차단(블랙리스트)하는 것이 필요할 수 있습니다. 이는 해당 장치를 vfio-pci 모듈에 바인딩하기 위해 필요합니다. 블랙리스트를 설정하지 않으면, 기본 드라이버가 장치를 사용하게 되어 PCI 패스스루가 제대로 작동하지 않을 수 있습니다. -
OVMF
OVMF(Open Virtual Machine Firmware)는 UEFI(Unified Extensible Firmware Interface) 펌웨어의 가상화된 구현입니다. 이는 가상 머신(VM)에서 UEFI를 사용할 수 있도록 합니다. UEFI는 기존의 BIOS를 대체하는 최신 펌웨어 인터페이스로, 하드웨어 초기화, 운영 체제 로드 및 시스템 서비스를 관리합니다. OVMF는 특히 KVM/QEMU와 같은 가상화 플랫폼에서 사용됩니다.
acquiring lock * for container
 |
|---|
| 아침에 봤더니 이모양이다. |
ERRO[0000] Refreshing container 51761aec6dfe3ef8bd04b4bbff9625956787b37fbe248d654703462ca7a9ad4e: acquiring lock 2 for container 51761aec6dfe3ef8bd04b4bbff9625956787b37fbe248d654703462ca7a9ad4e: file exists
문제가 무엇인지 찾아본다.
- Github에서 누간가 질문한 글에서 유추하기를 Podman의 경우 root가 아닌 계정으로 작동하기 때문에 발생하는 것으로 보인다.
- loginctl이라는 녀석이 유용해 보인다.
GPT에게 질문해본다.
loginctl enable-linger 명령은 사용자가 시스템에 로그아웃한 후에도 그 사용자의 서비스가 계속 실행될 수 있도록 설정합니다. 이는 특히 rootless(비루트) Podman과 같은 도구를 사용할 때 유용합니다. 사용자가 로그아웃할 때 systemd가 사용자 세션과 관련된 리소스를 정리하지 않도록 하여 Podman 프로세스가 중단되지 않게 합니다.
setbool + httpd_can_network_connect
 |
|---|
| Nginx-Proxy 설정에 문제가 생긴다. |
처음에는 뭐가 문제인지 몰랐다. (이전에 사용하던 conf 파일을 집어넣었는데 말이다.)
$ getsebool -a | grep httpd_can_network
httpd_can_network_connect --> off
이 모든것이 SELinux에 대한 경험이 부족한 것에서 비롯되는 것이 아닌가 한다.
 |
|---|
| 그리고 모든 것은 로그에서 출발한다. |
Podman + iptable
 |
|---|
| Podman에서 Run했을때 마주한 에러 |
이런저런 사정으로 서버 전체를 다시구성하고 있는데, 뭔가 Ubuntu보다는 Rocky가 나은거 같아서 이번에도 선택을 했더니 알 수 없는 메시지를 뿌린다.
ERRO[0000] Starting some container dependencies
ERRO[0000] "netavark: code: 3, msg: modprobe: ERROR: could not insert 'ip_tables': Operation not permitted\niptables v1.8.10 (legacy): can't initialize iptables table `nat': Table does not exist (do you need to insmod?)\nPerhaps iptables or your kernel needs to be upgraded.\n"
Error: starting some containers: internal libpod error
좀 읽어보면 iptable에 insert를 못했다는 이야기인데.. 이제까지 환경설정하면서 처음 만나는 상황이 아닌가 싶다.
HASS + Sonoff
Image Sample
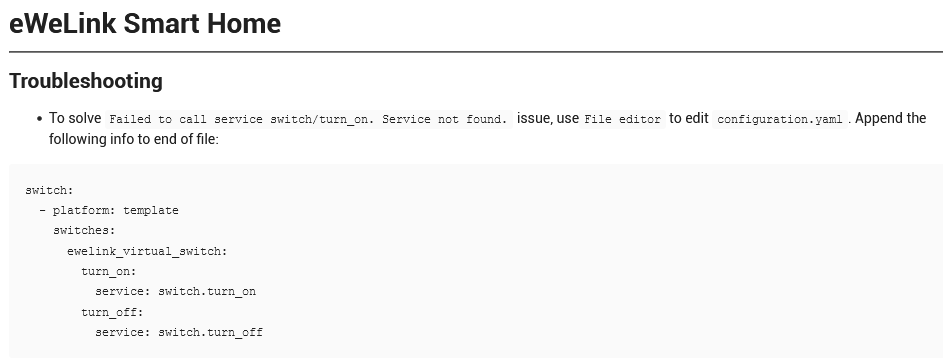 |
|---|
| configuration.yaml을 바꾸라는 정성스런 이미지. |
HASS OS를 올리고 sonoff를 위해 eWelink를 설치한것 까지는 좋았는데, 이 녀석이 동작을 안한다.
switch.turn_on을 찾을 수 없다는 메시지만 보여주고 답이 없다.
웃기는건 이전 버전에 어찌어찌 설치한 녀석들은 좀 야매스러워도 즉각 반응하는 것이 좀 이상했다.
약간의 구글링을 통해서 이 답변을 보고 configuration.yaml을 어찌 찾을 수 있을까 생각 해보니 SSH Addon이 보여서 설치하고 들어가.. 어 이미지에 있는 설정을 한땀 한땀 키인하고 재시작을 했더니 잘 적용이 된다.
HASS OS + Rpi3B
 |
|---|
| HASS OS Boot Image |
얼마전 NAS로 사용하고 있던 Ubuntu의 메모리가 2G인 것을 보고 깜짝 놀랐다. 최소 4G는 끼워준것같았는데.. 거기서 돌리고 있던 각종 서비스를 생각하면 너무한가 싶기도 하고 전혀 불편을 모르고 있었다는 것이 말이다.
지금 확인해봐도 1G사용에 800M cache다
토요일 처음 시작은 거실에서 사용하던 Rpi3+MPD에 Creative Roar2 Speaker를 USB로 붙이는 것이었는데, 자연스럽게 인식하던 Audio Engin2+와 다르게 usb device는 인식이 되는데 audio card에는 올라오지 않는다.
자 이렇게 뭔가 뜻하던 것이 안되는 상황이 되면, 그것을 해결하기 위해서 문제를 더 크게 만드는 재주가 있는듯 하다.
Swagger에 Google oAuth를 적용하며
Swagger에 Google oAuth를 적용하는 시도를 하고있었다.
대충 다 맞게 적용한거 같은데 자꾸만 redirect_uri_mismatch를 반환하는 것이다.
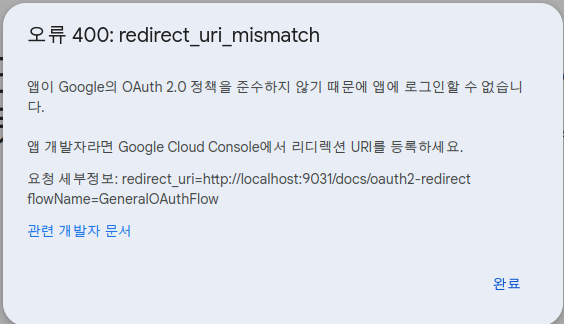 |
|---|
| Swagge에서 보여주는 메시지 |
Google Console에서 설정하려고 아무생각없이 긁었는데.. 그게 문제다.
http://localhost:9031/docs/oauth2-redirect flowName=GeneralOAuthFlow
중간에 공백이 왜 있을까? 고민을 살짝 했으나.. 출력의 문제라고 판단하고
http://localhost:9031/docs/oauth2-redirect?flowName=GeneralOAuthFlow
당연히 될 일이 아니다.
결론은 아래와 같다.
http://localhost:9031/docs/oauth2-redirect
안내 메시지의 출력시 개행은 항상 중요하다.
요청 세부정보:
redirect_uri=http://localhost:9031/docs/oauth2-redirect
flowName=GeneralOAuthFlow
Memory 8G
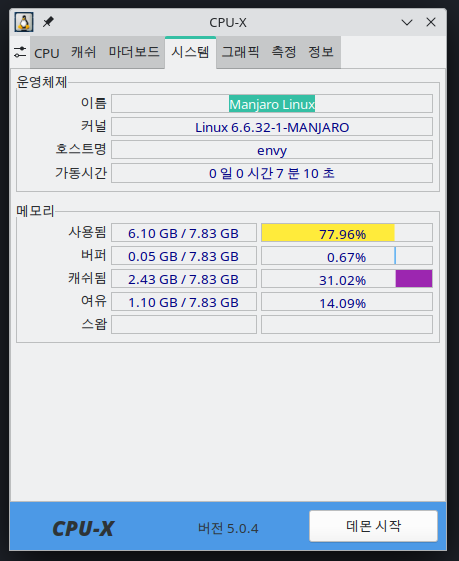 |
|---|
| cpu-x |
개인적으로 사용하고 있는 개발 노트북 녀석이 자꾸 죽어서 이상하다 생각하지 않고(AMD Vega Driver 이슈라고 막연히 생각) 있다가 혹시나 하는 생각에 메모리를 봤더니 8G.
음..
이 상태에서 Oracle XE를 올리고 몇 가지 서비스를 마구 올렸더니 뭔가 아주 느려지는 현상을 보여서 다 되서 그런가 보다 하고 있었는데..
많이 힘들었나 보다.
Memory 확인하는 명령어
Arch인 경우 pamac로 설치하면 된다. cpu-x dmidecode -t 17 (17번이 메모리인가 보다)
harlequin/dblab + Oracle
Github: Oracle + harlequin
Github: Oracle + dblab
1st
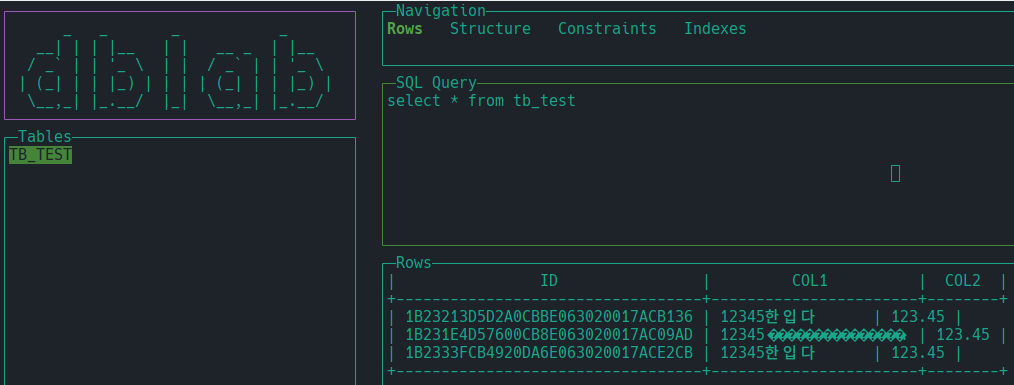 |
|---|
| Oracle + dblab |
“한글"에서 “글"이 사라졌다. 뭐.. 깨지는 거야 입출력 Char Set이 안맞아서 그런다하지만 말이다.
2st
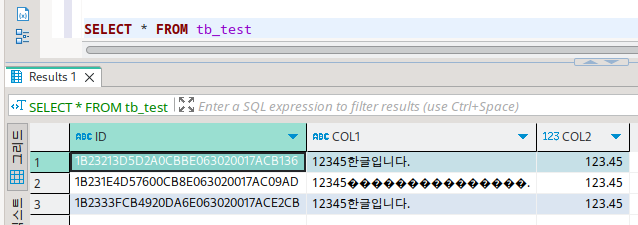 |
|---|
| Oracle + dbeaver |
| 중간에 깨진 한글은 init.sql로 입력한 것이다. |
3st
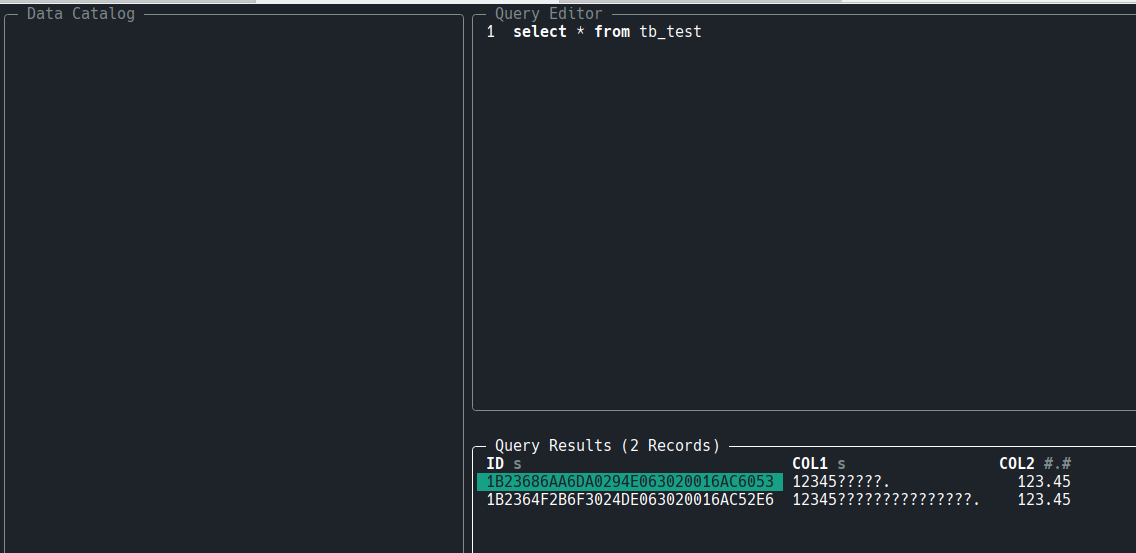 |
|---|
| Oracle + harlequin |
| sqlplus로 입력한 것, dbeaver에서 입력한것. 아무 설정도 하지 않은 상태에서 보는 것은 좀 무리가 있다. |
4st
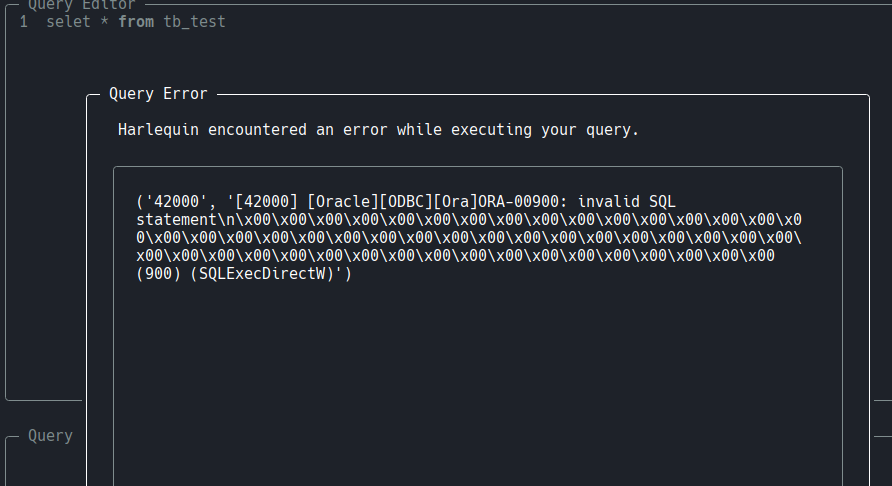 |
|---|
| Oracle + harlequin |
| harlequin으로 입력하고 난 다음 select로 혹시나 입력되었나 찾아보는 것. |
결론
한 이틀동안 신나게 Oracle을 설정하면서 재미나게 놀았으나, Oralce Docker내부에 Terminal SQL Client를 내재하는것은 딱히 sqlplus에 비해서 나은점이 없는 것으로 보인다.
startup은 되는데 setup은 안되는 이유? (Docker+OracleXE)
startup은 되는데 setup은 안된다.
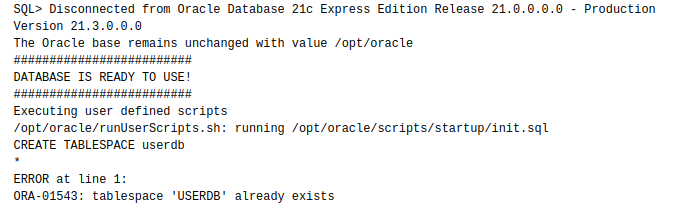 |
|---|
| 컨테이너를 시작 할 때마다 Script가 실행되고 있다. 이걸 바라는건 아니다. |
Oracle Docker Image설명에도 분명하게 나와있는 사항이기는 한데.
Docker Image를 만들면서 초기 Script를 넣어두는 작업을 하다가 보니 startup에 넣어둔 sql은 매번 구동이 되는데, setup에 넣어둔 sql은 처음 한 번만 실행 될 것을 기대했으나. (실행이)안된다.
setup에 DBMS, User를 생성하는 SQL을 넣어두러고 했던 것이다.
포기하고 다른 방법을 찾는다.
 |
|---|
| 빌드를 완료하고 화면상에 스크립트를 호출하는 명령을 출력한다. |
하루정도 투자 해서 이리해보고 저리해보다 포기하고 궁여지책으로 명령어를 출력하는 것으로 한다. 알아서 잘 사용해야 한다.
Jekyll + Docker
Blog를 Jekyll로 설정하고 나서, 여러 환경에서 글을 쓰고 deploy하는 것이 살짝 어렵고 있었다.
다른건 그러려니 하는데 매번 Ruby와 Jekyll을 설정하는 것이 번거롭다고 느낀것이다.
환경을 Docker로 올리려고 하다가 보니.
- Jekyll image가 한 번에 올라오지 않았다
- Ruby image도 안된다
결국 날 Ubuntu에 한땀 한땀 설치를 해 보기로 한다.
이러저런 시도끝에 문제가 되는 부분은 mini_racer라는 Gem이 참조하는 node의 folder명에 대한 것이었다.
/usr/bin/ld: cannot find /var/lib/gems/3.2.0/gems/libv8-node-21.7.2.0-x86_64-linux/vendor/v8/x86_64-linux-gnu/libv8/obj/libv8_monolith.a: No such file or directory
libv8-node를 설치하면 “x86_64-linux"이라는 폴더가 구성이 되는데 mini_racer는 “x86_64-linux-gnu"라는 것에서 libv8_monolith.a 파일을 찾고있는 문제인 것이다.
Jekyll VSCode Extension
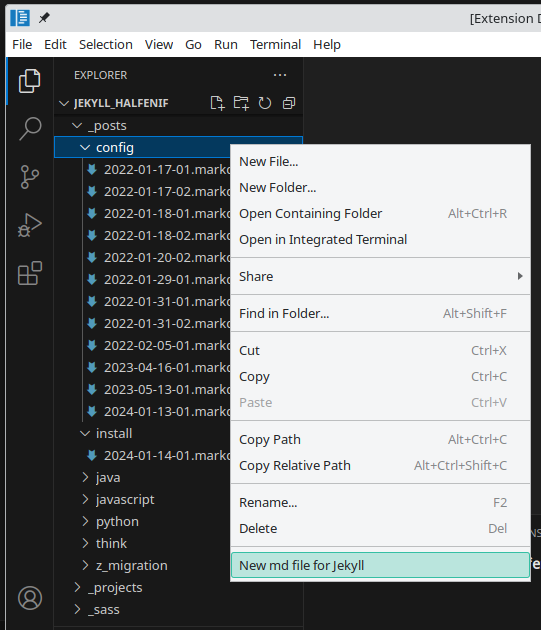 |
|---|
| VSCode에서 실행한 메뉴 |
증미에서 프로젝트를 수행하는 동안 이것저것 만들고나서는 블로그에 갱신하려고 보니 여간 귀찬은 것이 아니다.
그 귀찬음의 가장 주요한 원인을 가만 생각해보니, 하나의 post를 만들 때 마다, markdown파일을 복사하고 에디팅하고.. 지친 다음에 글을 쓰고자 했던 것이다.
일전에 Jekyll Admin을 시도해봤지만, 내 취향은 아니었고.
그래서 VSCode Extension을 만들기로 한다.
가장 기본적인 내용은 MS가 제공하는 Your First Extension에 다 나와있으나, GPT의 힘을 살짝 빌려 만들어본다.
- package.json에서 vscode version을 변경하는 것으로 거의 모든 문제를 해결 할 수 있다.
- 만들어진 extension을 게시 할 것인지 고민했으나.. vsce를 설치하고 *.vsix 파일로 제공하는 것이 더 현실적이라 생각해서 그렇게 한다.
Jekyll-Admin을 발견하다
Headless CMS쪽을 살펴보다 Jekyll-Admin이라는 녀석을 발견했다.
재미있다 생각하고 설치를 해보고, 어찌 사용을 해 보려 하는데..
그냥 VSCode에서 snippet을 설정하는게 속편하겠다는 생각이 드는 이유는 뭔가 싶다.
VSCode+Snipet+ShortCut
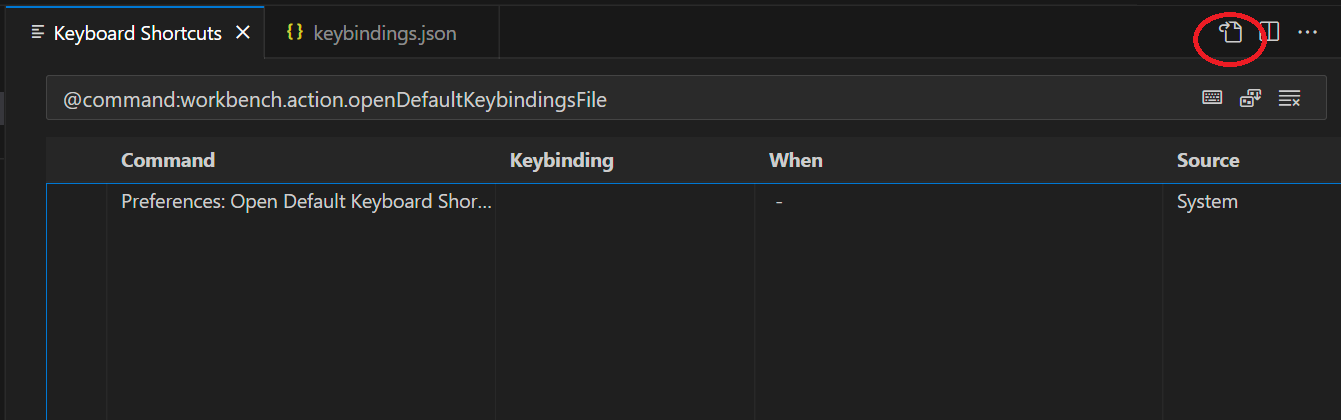 |
|---|
| ShortCut JSON을 설정하는 버튼이.. |
지금 진행하는 프로젝트에서 매번 브랜치를 따고 있는데, 서로 약속한 브랜치명이 있다보니, 매번 에디팅하는 것을 귀찬아 하다 토요일 저녁 VSCode의 ShortCut을 사용하기로 하고 찾아보는데, 도저히 어떻게 설정을 했었는지 기억나지 않는다.
한참을 찾다, 결국 저 이미지상의 우측상단 아이콘을 누르는 것으로 모든 해결점을 찾아..
기억은 점점 흐릿해져간다.
Ubuntu Pro
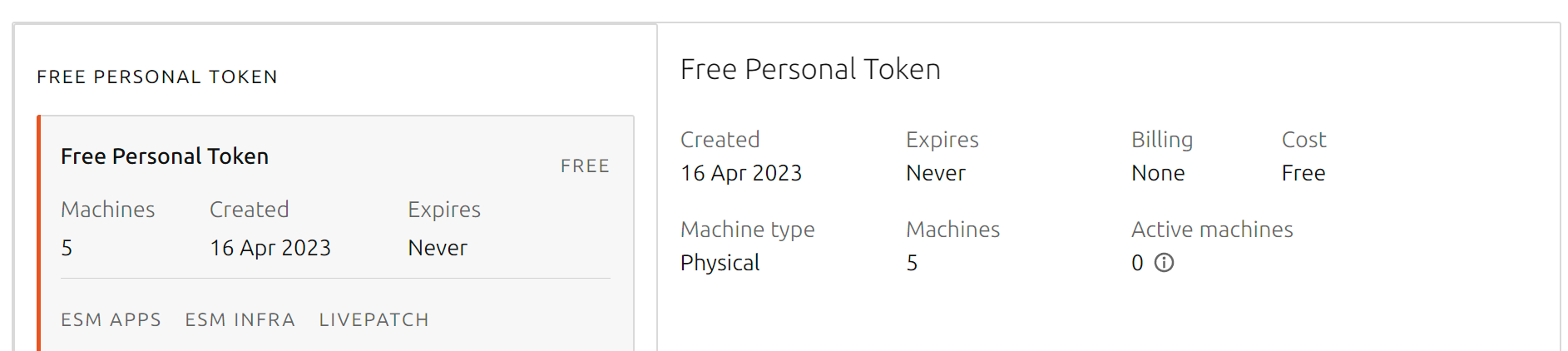 |
|---|
| Ubuntu Pro를 설정하고 |
일요일 아침 일어나 과거의 블로그 글을 밀어넣으려고하다 보니 원격의 서버에 자연스럽게 접근을 하는데, Ubuntu에서 Pro라는 컨셉을 광고하고 있다.
잠깐 찾아보다 개인사용으로는 무료라 하니 적용 해 본다.
VSCode + .editorconfig 그리고 quote
토요일.
javaScript로 개발을 한다는 것이 (아마도) 엄청난 성장기라 그런지 개발환경에 대한 설정과 설정 그리고 설정을 하면서 배우고 또 배우는 상황인듯 하다.
기존에 만들고 있던 Toy Project에 eslint와 prettier를 적용하면서 잘될거라는 기대도 없었지만 역시나 역시나 멀쩡히 잘 되던 부분이 안되는 현상이 있어 몇 시간 삽질을 하다가 Pure한 Template을 다시 구해서 해보고 결국 설정이라는 생각을 하고 있다.
Vite + Vu3 + eslint + prettier + VSCode 설정의 대환장파티를 히루 종일 해 보고 남은 건.
Server에 vite로 build한 것 배포하기
월요일.
만들고있는 Toy Project(빨리 이름을 지어줘야 겠다.)를 배포하려고 보니..
운영서버에 node가 설치될 이유가 있는가?
- 나는 정적인 웹서버로 Nginx를 사용 할 예정이니, Node가 필요한 상황은 아니다
# 그러니 NPM을 설치할 이유는 없어 보인다.
- 빌드결과물을 어떻게 Cloud에 올릴 것인가?
# 개발환경이나 혼자 막 쓰는 녀석이라면 Github을 통해서 간편하게 구성 할 수 있겠지만.
scp를 사용하기로 하고 설정을 한다.
# WSL에서
# Key는 미리 등록되어 있어야 한다. 사용자명은 ubuntu라고하면
# build된 결과물이 dist에 있고, cloud에서는 ~/temp/front에서 작업 할 것이다.
tar -cvzf dist.tar.gz dist/
scp -i ~/.ssh/키파일명 dist.tar.gz ubuntu@클라우드IP:temp/front/dist.tar.gz
# Cloud에서
# Nginx Root Folder에 대한 권한 작업은 되어 있어야 한다
# 다 지우고 넣는다. 잘 생각하자.
rm -rf dist
tar -xvf dist.tar.gz
rm -rf /var/www/html/*
cp -r ./dist/* /var/www/html
Key File을 매번 입력하기 싫으면, .ssh에 config File을 만들어두면 간편하게 사용 할 수 있기는 하다. (나는 그렇게 쓰고 있다.)
Oracle Cloud SSH Key & IP Table
월요일. 음력으로는 올해의 마지막 날.
무료로 제공해줘서 잘쓰고 있는 오라클 클라우드 인스턴스에 지금 만들고 있는 Toy Project를 올리려고 작업을 한다.
- 인스턴스를 만들 때 Private Key File을 받아놓자.
Public Key를 받아놓을 필요가 있을까?
아직까지는 그런 경우를 알지 못한다.
- Windows는 좀 그러니 WSL ssh folder에 밀어넣고 600으로 퍼미션을 변경 해 둔다. 안그러면 퍼미션관련 오류메시지를 볼 것이다.
//WSL에서
chmod 600 파일명
- default user는 Ubuntu의 경우 ubuntu이다. 자기 id 넣고, 순간 당황하지 말자.
이게 습관이라는 것이 참 무서운것이다.
뭐가 문제인지 인식하는데 시간이 좀 걸렸다.
- 방화벽 정책을 등록하고. (이미 다른 인스턴스가 있으면 함께 적용가능 하다.)
//Web Instance 관리화면에서
Networking >> Virtual Cloud Networks >> 해당VNC >> Subnet Details
여기 Security Lists에 추가한다.
- IP Table을 열어준다
//Instance에서
sudo iptables -I INPUT 5 -i ens3 -p tcp --dport 포트번호 -m state --state NEW,ESTABLISHED -j ACCEPT
- 재부팅시에도 설정을 유지하도록 하고 재부팅해서 확인한다. (확인은 반드시 실행해서 확인해보는..좀 위험한 발상이기는 하다만.)
//Instance에서
sudo apt install iptables-persistent
sudo netfilter-persistent save
sudo reboot
VSCode 단축키 설정
토요일.
VSCode를 주 개발도구로 바꾸고 나서, Python과 JavaScript를 동시에 사용하다가 보니, Python에서 Console.log()를 찍고 있고, JavaScript에서 print()를 찍고 있는게 당연한건 아니다.
귀찬으면 뭔가 개선을 해야 해서 좀 찾아보니 VSCode Snipet에 잘 정리가 되어 있다.
[
{
"key": "ctrl+shift+a",
"command": "editor.action.insertSnippet",
"when": "editorTextFocus",
"args": {
"snippet": "console.log(`${CLIPBOARD}:`,${CLIPBOARD});"
}
},
{
"key": "ctrl+shift+z",
"command": "editor.action.insertSnippet",
"when": "editorTextFocus",
"args": {
"snippet": "print(f'${CLIPBOARD}:', $CLIPBOARD)"
}
}
]
일단 내가 사용하는 스타일을 보니 변수명을 복사 한 다음 그 녀석을 찍어보겠다는 생각이니, 손가락이 가까운 a와 z를 하나씩 각인시켜본다.
Nginx를 활용하는 개발, 테스트서버의 설정(Feat. FastAPI, Vite)
목요일.
Toy Project를 하나 만들고 있는데, 이 녀석을 FastAPI와 Vite로 구성하고 (관리의 편의라는 이름으로) 하나의 git project로 관리하고 있다.
root
- api
.gitignore
- __pycache__
api.py
- ui
.gitignore
- node_modules
index.html
개발 할 때는 api 폴더에 들어가서 uvicorn으로 api.py를 구동시켜 http://localhost:8000으로 API서버를 올리고, ui폴더로 들어가서 npm run dev로 http://localhost:3000의 (Static) Web Server를 구동시킨다. 물론 npm run serve도 사용해야 한다.
여기에서 생각해야 하는 사항은
- CORS
- API Server URL
CORS는 FastAPI에서 가이드하는 부분으로 처리하면 되고, API Server URL부터는 좀 생각을 해야 한다.
나는 프론트와 백앤드를 하나의 오리진으로 서비스 하는 것으로 구성 하려고 하기 때문에, 개발 할 때 API서버의 주소와 운영 할 때 API서버의 주소가 상이한 상황이 발생한다.
Pretendard Web Font 설정하기
화요일.
점심을 먹고 운동을 하고 와서 개발관련 글을 읽고 있는데 폰트가 이쁘다고 생각하고 확인을 해 보니 Pretendard라는 녀석이어서 당연히 외산일것이라 생각하고 구글에서 검색을 하는데 한국인이 만든것인가 보다.
오전에 적용한 ‘D2Coding Web Font’는 이로서 2시간도 안되어 버려지게 되어 버렸다.
Font/CSS설치
Pretendard Font를 받아서 적당한 Font 폴더에 넣는다.
나는 woff2만 지원 할 것이지만 css를 살펴보니 size에 따라 적당한 폰트가 다 따로 있는듯 해서 static woff2 전부를 받았다.Pretendard css를 받아서 적당한 css 폴더에 넣고 경로를 변경해준다.
적용하기
이건 자신이 처한 jekyll 테마 환경마다 다를 것이나, minima 2022-01-18기준으로..
D2Coding을 Web Font로 설정하는 작업
화요일.
일이 이상하게 돌아가고 있다.(그냥 적용해본 구글 Web Font “Noto Sans KR"가 마음에 안든거다.)
무슨 생각이었을까? 갑자기 D2Coding Font를 이 웹페이지에 적용해야 겠다고 생각하고 구글링을 해 보니 먼저 시도 한 사람이 있다.
알아야 할 사항
- woff2, woff, ttf (브라우저 지원을 위한 선택)
- full, subset (Size를 줄이기 위한 선택)
웹 폰트 사용과 최적화의 최근 동향을 읽어보면 브라우저 지원을 위해서는 woff2와 woff까지 가지고 있어야 할 거 같은데, 그냥 woff2만 지원하기로 한다. (현재 Edge에서 테스트 해보니 woff2를 사용했기 때문에 나머지 브라우저에서 이상하게 보이는건 어쩔수없다.)
Github Page에 Web Font를 적용하기 위한 설정
월요일.
Github Page를 사용하기로 하고 글을쓰는것에서 다 좋은대 PC로 봤을 때 font가 마음에 안든다.(모바일에서 보는 것은 좋았다.)
Google에서 제공하는 Web Font를 설정하려고 봤더니 간단하게 해결될 문제가 아니라는 생각이 들었다. 사실 이 문제는 공개되어 있는 테마중에 미려한 녀석을 선택해서 사용하면 간단하게 해결된 문제지만, 나는 그럴 생각이 없음으로 내 손으로 해결을 해야한다.
이런 작업을 하기에 2가지 사항을 해결해야 했다.
- Jekyll의 기본테마인 minima에 Web Font를 적용시키는 방법
- Local에서 작업을 했더라도 Github Page에 Push했을 때 의도대로 동작하도록 환경을 일치시키는것
jekyll 버전일치
일단 Github Page에서 Jekyll을 사용해서 서빙을 하고 있기 때문에 Github이 제공하는 환경과 내가 가진 환경의 차이점을 없애는 부분을 먼저 검토해보니 Jekyll버전부터가 다르다.
sudo gem install jekyll -v 3.9.0
gem도 install을 지원하기 때문에 적당한 버전의 jekyll을 다시 설치 해 준다.
WSL에서 port개방이 안될때
월요일.
개발환경을 WSL에 설정하면서 서버를 구동하고 웹브라우저로 확인을하던 디버깅을 하던 필연적으로 WSL과 Host Window사이의 port를 개방해야 하는 문제에 직면하게 된다.
당연히 구글에 찾아보면 PowerShell로 만들어진 스크립트를 손쉽게 입수 할 수 있지만, 그 어디에도 (그렇게 해도) 안될때에 대한 이야기나 추가적인 사항에 대해서 언급한 포스팅은 본적이 없어 잠시 해메다가 이 글을 적어본다.
먼저 아래에 기술한 Script를 확장자 ps1으로 저장을 하고 스크립트의 내용을 살펴보자.
$remoteport = bash.exe -c "ifconfig eth0 | grep 'inet '"
여기에서 중요한 부분은 bash.exe가 의미하는것이 Window말고 Linux에서 실행할것이라는 의미이다. 그러니 뒤쪽에 있는 파라메터중 ifconfig는 linux command이다.
불행하게도 Ubuntu기준으로 저 녀석은 기본설치가 아니고 net-tools에 포함되어 있다. linux에서 apt로 설치해줘야 한다.